- Research Article
- Open access
- Published:
Anonymous Biometric Access Control
EURASIP Journal on Information Security volume 2009, Article number: 865259 (2009)
Abstract
Access control systems using the latest biometric technologies can offer a higher level of security than conventional password-based systems. Their widespread deployments, however, can severely undermine individuals' rights of privacy. Biometric signals are immutable and can be exploited to associate individuals' identities to sensitive personal records across disparate databases. In this paper, we propose the Anonymous Biometric Access Control (ABAC) system to protect user anonymity. The ABAC system uses novel Homomorphic Encryption (HE) based protocols to verify membership of a user without knowing his/her true identity. To make HE-based protocols scalable to large biometric databases, we propose the  -Anonymous Quantization (kAQ) framework that provides an effective and secure tradeoff of privacy and complexity. kAQ limits server's knowledge of the user to
-Anonymous Quantization (kAQ) framework that provides an effective and secure tradeoff of privacy and complexity. kAQ limits server's knowledge of the user to  maximally dissimilar candidates in the database, where k controls the amount of complexity-privacy tradeoff. kAQ is realized by a constant-time table lookup to identity the
maximally dissimilar candidates in the database, where k controls the amount of complexity-privacy tradeoff. kAQ is realized by a constant-time table lookup to identity the  candidates followed by a HE-based matching protocol applied only on these candidates. The maximal dissimilarity protects privacy by destroying any similarity patterns among the returned candidates. Experimental results on iris biometrics demonstrate the validity of our framework and illustrate a practical implementation of an anonymous biometric system.
candidates followed by a HE-based matching protocol applied only on these candidates. The maximal dissimilarity protects privacy by destroying any similarity patterns among the returned candidates. Experimental results on iris biometrics demonstrate the validity of our framework and illustrate a practical implementation of an anonymous biometric system.
1. Introduction
In the last thirty years, advances in computing technologies have brought dramatic improvements in collecting, storing, and sharing personal information among government agencies and private sectors. At the same time, new forms of privacy invasion begin to enter the public consciousness. From sale of personal information to identity theft, from credit card fraud to YouTube surrendering user data [1], the number of ways that our privacy can be violated increases rapidly.
One important area of growing concern is the protection of sensitive information in various access control systems. Access control in a distributed client-server system can generally be implemented by requesting digital credentials of the user wanting to access the system. Credentials are composed of attributes that contain identifiable information about a given user. Such information can be very sensitive and uncontrolled disclosure of such attributes can result in many forms of privacy breaches. It is unsurprising that privacy protection has been a central concern in widespread deployment of access control systems, especially in many of the e-commerce applications [2].
Among the different types of access control systems, Biometric Access Control (BAC) systems pose the most direct threat to privacy. BAC systems control allocation of resources based on highlydiscriminative physical characteristics of the user such as fingerprints, iris images, voice patterns, or even DNA sequences. As a biometric signal is based on "who you are" rather than "what you have," BAC systems excel in authenticating a user's identity. While the use of biometrics enhances system security and alleviates users from carrying identity cards or remembering passwords, it creates a conundrum for privacy advocates as the knowledge of the identity makes it much harder to keep users anonymous. A curious system operator or a parasitic hacker can infer the identity of a user based on his/her biometric probe. Furthermore, as biometrics is immutable from systems to systems, it can be used by attackers to cross-correlate disparate databases and cause damages far beyond the coverage of any protection schemes for individual database systems.
A moment of thought reveals that many access control systems do not need the true identity of the user but simply require a confirmation that the user is a legitimate member. For example, an online movie vendor may have a category of "VIP" members who pay a flat monthly membership fee and can enjoy an unlimited number of movies download. While it is important to verify the VIP status of a candidate user, it is unnecessary to precisely identify who the user is. In fact, it will be appeasing to customers if the vendor can provide a guarantee that it can never track their movie selections. Entry control of a large office building that hosts many companies can also benefit from such an anonymous access control system. While it is essential to restrict entry only to authorized personnel, individual companies may be reluctant to turn over sensitive identity information to the building management. Thus a system that can validate the tenant status of a person entering the building without knowing the true identity will be valuable. Another example is a community electronic message board. Only the members of the community can sign in to the system. Once their member status are verified, they can anonymously post messages and complaints to the entire community. All the aforementioned examples can benefit from an access control system that can verify the membership status using biometric signals while keeping the identity anonymous.
In this paper, we introduce Anonymous Biometric Access Control (ABAC) to provide anonymity and access control in such a way that the system server (Bob) can authenticate the membership status of a user (Alice) but cannot differentiate Alice from any other authorized users in his database. Our scheme differs from other work in privacy protection of biometric systems which focus primarily on the security of the biometric data from improper access. Our goal is to guarantee user's anonymity while providing the safeguard of the system resources similar to other access control systems.
In this paper, we consider two technical challenges in developing an ABAC system. First, to cope with the variability of the input probe, any biometric access system needs to perform a signal matching process between the probe and all the records in the database. The challenge here lies in making the process secure so that Bob can confirm the membership status of Alice without knowing any additional information about Alice's probe. We cast this process as a secure multiparty computation problem and develop a novel protocol based on homomorphic encryption. Such a procedure prevents Bob from extracting any knowledge about Alice's probe and its similarity distances with any records in Bob's database. On the other hand, Bob can compare the distances to a similarity threshold in the encrypted domain and the comparison results are aggregated into two secret numbers shared between Bob and Alice. The secret share held by Bob prevents Alice from cheating and Alice's membership status can be verified by Bob without knowing her identity.
Second, we consider the complexity challenge posed by scaling the matching process in encrypted domain to large databases. The high complexity of cryptographic primitives is often cited as the major obstacle of their widespread deployment in realistic systems. This is particularly true for biometric applications that require matching a large number of high-dimensional feature vectors in real time. In this paper, we propose a novel framework to provide a controllable trade-off between privacy and complexity. We call the framework  -anonymous ABAC system (
-anonymous ABAC system ( -ABAC) which keeps Alice anonymous from
-ABAC) which keeps Alice anonymous from  , rather than the entire database of, authorized members in the database. This is similar to the well-known
, rather than the entire database of, authorized members in the database. This is similar to the well-known  -anonymity model [3] in that
-anonymity model [3] in that  is a controllable parameter of anonymity. However, the two approaches are fundamentally different—the
is a controllable parameter of anonymity. However, the two approaches are fundamentally different—the  -anonymity model is a data disclosure protocol where Bob anonymizes the database for public release by grouping all the data into
-anonymity model is a data disclosure protocol where Bob anonymizes the database for public release by grouping all the data into  -member clusters. In a
-member clusters. In a  -ABAC system, the goal is to prevent Bob from obtaining information about the similarity relationship between his data and the query probe from Alice. In order to minimize the knowledge revealed by any
-ABAC system, the goal is to prevent Bob from obtaining information about the similarity relationship between his data and the query probe from Alice. In order to minimize the knowledge revealed by any  -member cluster, we propose a novel grouping scheme called
-member cluster, we propose a novel grouping scheme called  -Anonymous Quantization (kAQ) that optimizes the dissimilarity among members in the same group. kAQ forbids similar patterns to be in the same group which might be a result of multiple registrations of the same person or from family members with similar biometric features. The kAQ process is carried out mostly in plaintext and is computationally efficient. Using kAQ as a preprocessing step, the subsequent encrypted-domain matching can be efficiently realized within the real-time constraint.
-Anonymous Quantization (kAQ) that optimizes the dissimilarity among members in the same group. kAQ forbids similar patterns to be in the same group which might be a result of multiple registrations of the same person or from family members with similar biometric features. The kAQ process is carried out mostly in plaintext and is computationally efficient. Using kAQ as a preprocessing step, the subsequent encrypted-domain matching can be efficiently realized within the real-time constraint.
The rest of the paper is organized as follows. After reviewing related work in Section 2, we provide the necessary background in the security models for anonymous biometric matching, homomorphic encryption, and dimension reduction in Section 3. We first provide an overview of the entire system in Section 4. The design of ABAC using homomorphic encryption is presented in Section 5. In Section 6, we introduce the concepts of kABAC and  -Anonymous Quantization. We also describe a greedy algorithm to realize kAQ and show a secure procedure to perform quantization without revealing private information. To demonstrate the viability of our approach, we have tested our system using a large collection of iris patterns. The details of the experiments and the results are presented in Section 7. We conclude the paper and discuss future work in Section 8.
-Anonymous Quantization. We also describe a greedy algorithm to realize kAQ and show a secure procedure to perform quantization without revealing private information. To demonstrate the viability of our approach, we have tested our system using a large collection of iris patterns. The details of the experiments and the results are presented in Section 7. We conclude the paper and discuss future work in Section 8.
2. Related Work
The main contributions of our paper are the introduction of the ABAC system concept and a practical design of such a system using iris biometrics. There are other work that deal with the privacy and security issues in biometric systems but their focus is different from this paper. A privacy-protecting technology called "Cancelable Biometrics" has been proposed in [4]. To protect the security of the raw biometric signals, a cancelable biometric system distorts a biometric signal using a specially designed noninvertible transform so that similarity comparison can still be performed after distortion. Biometric Encryption (BE) described in [5] possesses all the functionality of Cancelable Biometrics, and is immune against the substitution attack because it outputs a key which is securely bound to a biometric. The BE templates stored in the gallery have been shown to protect both the biometrics themselves and the keys. The stored BE template is also called "helper data". "Helper data" is also used in [6] to assist in aligning a probe with the template that is available only in the transformed domain and does not reveal any information about the fingerprint.
All the above technologies focus on the security and privacy of the biometric signals in the gallery. Instead of storing the original biometric signal, they keep only the transformed and noninvertible feature or helper data extracted from the original signal that do not compromise the security of the system even if they are stolen. In these systems, the identity of the user is always recognized by the system after the biometric matching is performed. To the best of our knowledge, there are no other biometric access systems that can provide access control and yet keep the user anonymous. Though our focus is on user anonymity, our design is complementary to cancelable biometrics and it is conceivable to combine features from both types of systems to achieve both data security and user anonymity.
Anonymity in biometric features like faces is considered in [7]. Face images are obfuscated by a face deidentification algorithm in such a way that any face recognition softwares will not be able to reliably recognize deidentified faces. The model used in [7] is the celebrated  -anonymity model which states that any pattern matching algorithm cannot differentiate an entry in a large dataset from at least
-anonymity model which states that any pattern matching algorithm cannot differentiate an entry in a large dataset from at least  other entries [3, 8]. The
other entries [3, 8]. The  -anonymity model is designed for data disclosure protocols and cannot be used for biometric matching for a number of reasons. First, despite the goal of keeping the user anonymous, it is very important of an ABAC system to verify that a user is indeed in the system. Face de-identification techniques provide no guarantee that only faces in the original database will match the de-identified ones. As such, an imposter may gain access by sending an image that is close to an de-identified face. Second, de-identification techniques group similar faces together to facilitate the public disclosure of the data. This is detrimental to anonymity as face clusters may reveal important identity traits like skin color, facial structure, and so forth.
-anonymity model is designed for data disclosure protocols and cannot be used for biometric matching for a number of reasons. First, despite the goal of keeping the user anonymous, it is very important of an ABAC system to verify that a user is indeed in the system. Face de-identification techniques provide no guarantee that only faces in the original database will match the de-identified ones. As such, an imposter may gain access by sending an image that is close to an de-identified face. Second, de-identification techniques group similar faces together to facilitate the public disclosure of the data. This is detrimental to anonymity as face clusters may reveal important identity traits like skin color, facial structure, and so forth.
Another key difference between anonymity in data disclosure and biometric matching is the need for secure collaboration between two parties—the biometric server and the user. The formal study of such a problem is Secure Multiparty Computation (SMC). SMC is one of the most active research areas in cryptography and has wide applications in electronic voting, online bidding, keyword search, and anonymous routing. While there are no previous work that use SMC for biometric matching, many of the basic components in a BAC system can be made secure under this paradigm. They include inner product [9, 10], polynomial evaluation [11–13], thresholding [14–16], median [17], matrix computation [18, 19], logical manipulation [20],  -means clustering [21, 22], decision tree [23–25] and other classifiers [12, 26–28]. A recent tutorial in SMC for signal processing community can be found in [29].
-means clustering [21, 22], decision tree [23–25] and other classifiers [12, 26–28]. A recent tutorial in SMC for signal processing community can be found in [29].
The main hurdle in applying computationally-secure SMC protocols to biometric matching is their high computational complexity. For example, the classical solution to the thresholding problem (this problem is commonly referred to as the Secure Millionaire Problem in SMC literature), or comparing two private numbers  and
and  , is to use Oblivious Transfer (OT) [30]. OT is an SMC protocol for joint table lookup. The privacy of the function is guaranteed by having the entire table encrypted by a precomputed set of public keys and transmitted to the other party. The privacy of the selection of the table entry is protected based on obfuscating the correct public key among the dummy ones. Even with recent advances in reducing the computational and communication complexity [13, 17, 31–34], the large table size, the intensive encryption, and decryption operations render OT difficult for pixel or sample-level signal processing operations.
, is to use Oblivious Transfer (OT) [30]. OT is an SMC protocol for joint table lookup. The privacy of the function is guaranteed by having the entire table encrypted by a precomputed set of public keys and transmitted to the other party. The privacy of the selection of the table entry is protected based on obfuscating the correct public key among the dummy ones. Even with recent advances in reducing the computational and communication complexity [13, 17, 31–34], the large table size, the intensive encryption, and decryption operations render OT difficult for pixel or sample-level signal processing operations.
A faster but less general approach is to use Homomorphic Encryption (HE) which preserves certain operations in the encrypted domain [35]. Recently, the homomorphic encryption scheme is proposed by IBM and Stanford researcher C. Gentry has generated a great deal of excitement in using HE for encrypted domain processing [36]. He proposed using Ideal Lattices to develop a homomorphic encryption system that can preserve both addition and multiplication operations. This solves an open problem on whether there exists a semanticallysecure homomorphic encryption system that can preserve both addition and multiplication. On the other hand, his construction is based on protecting the simplest boolean circuit and its generalization to realistic application is questionable. In an interview, Gentry estimates that performing a Google search with encrypted keywords would increase the amount of computing time by about a trillion [37] and even this claim is already challenged by others to be too conservative [38].
More practical homomorphic encryptions such as Paillier cryptosystem can only support addition between two encrypted numbers, but do so over a much larger additive plaintext group, thus providing a wide dynamic range for computation [39]. Furthermore, as illustrated in Section 3, multiplication between encrypted numbers can be accomplished by randomization and interaction between parties. Recently, Paillier encryption is being applied in a number of fundamental signal processing building blocks [40] including basic classifiers [27] and Discrete Cosine Transform [41] in encrypted domain. Nevertheless, the public-key encryption and decryption processes in any homomorphic encryption still pose a formidable complexity hurdle to overcome. For example, the fastest thresholding result takes around 5 seconds to compare two 32-bit numbers using a modified Paillier encryption system with a key size of 1024 bits [14]. One of the goals of this paper is to utilize homomorphic encryption to construct a realistic biometric matching system that can tradeoff computation complexity with user anonymity in a provably secure fashion.
3. Background
We model any biometric signal  as an
as an  -dimensional vector from a feature space
-dimensional vector from a feature space  where
where  is a finite field. We also assume the existence of a commutative distance function
is a finite field. We also assume the existence of a commutative distance function  that measures the dissimilarity between two biometric signals. In order for the distance to be computable using the operators in the field, we assume
that measures the dissimilarity between two biometric signals. In order for the distance to be computable using the operators in the field, we assume  to be a subfield of
to be a subfield of  so that the components of the constituent vectors will be treated as real numbers in the distance computation. The most commonly used distance is the Euclidean distance:
so that the components of the constituent vectors will be treated as real numbers in the distance computation. The most commonly used distance is the Euclidean distance:

For the iris patterns used in our experiments,  is the binary field
is the binary field  and
and  is a modified hamming distance defined below [42]:
is a modified hamming distance defined below [42]:

where  denotes the XOR operation and
denotes the XOR operation and  denote the bitwise AND.
denote the bitwise AND.  and
and  are the corresponding mask binary vectors that mask the unusable portion of the irises due to occlusion by eyelids and eyelash, specular reflections, boundary artifacts of lenses, or poor signal-to-noise ratio. As the mask has substantial variation even among feature vectors captured from the same eye, we assume that the mask vectors do not disclose any identity information.
are the corresponding mask binary vectors that mask the unusable portion of the irises due to occlusion by eyelids and eyelash, specular reflections, boundary artifacts of lenses, or poor signal-to-noise ratio. As the mask has substantial variation even among feature vectors captured from the same eye, we assume that the mask vectors do not disclose any identity information.
The special distance function and the high dimension of many feature spaces make them less amenable to statistical analysis. There exist mapping functions that can project the feature space  into a lower-dimensional space
into a lower-dimensional space  such that the original distance can be approximated by the distance, usually Euclidean, in
such that the original distance can be approximated by the distance, usually Euclidean, in  . The most well-known technique is Principal Component Analysis (PCA) which is optimal if the original distance is Euclidean [43]. For general distances, mapping functions can be derived by two different approaches—the first approach is Multidimensional Scaling (MDS) in which an optimal mapping is derived based on minimizing the differences between the two distances over a finite dataset [44]. The second approach is based on distance relationship with random sets of points and include techniques such as Fastmap [45], Lipshcitz Embedding [46], and Local Sensitivity Hashing [47]. In our system, we use both PCA and Fastmap for their low computational complexity and good performance. Here we provide a brief review of the Fastmap procedure and will discuss its secure implementation in Section 6. Fastmap is an iterative procedure in which each step selects two random pivot objects
. The most well-known technique is Principal Component Analysis (PCA) which is optimal if the original distance is Euclidean [43]. For general distances, mapping functions can be derived by two different approaches—the first approach is Multidimensional Scaling (MDS) in which an optimal mapping is derived based on minimizing the differences between the two distances over a finite dataset [44]. The second approach is based on distance relationship with random sets of points and include techniques such as Fastmap [45], Lipshcitz Embedding [46], and Local Sensitivity Hashing [47]. In our system, we use both PCA and Fastmap for their low computational complexity and good performance. Here we provide a brief review of the Fastmap procedure and will discuss its secure implementation in Section 6. Fastmap is an iterative procedure in which each step selects two random pivot objects  and
and  and computes the projection
and computes the projection  for any data point
for any data point  as follows:
as follows:

The projection in (3) requires only distance relationships. A new distance is then computed by taking into account the existing projection:

where  and
and  are the projections of
are the projections of  and
and  , respectively. The same procedure can now be repeated using the new distance
, respectively. The same procedure can now be repeated using the new distance  . It has been demonstrated in [45] that using pivot objects that are far apart, the Euclidean distance in the projected space produces a reasonable approximation of the original distance of many different feature spaces.
. It has been demonstrated in [45] that using pivot objects that are far apart, the Euclidean distance in the projected space produces a reasonable approximation of the original distance of many different feature spaces.
Using a dissimilarity metric, we can now define the function of a biometric access control system. It is a computational process that involves two parties: a biometric server (Bob) and a user (Alice). Bob is assumed to have a database of  biometric signals
biometric signals  , where
, where  is the biometric signal of member
is the biometric signal of member  . Alice provides a probe
. Alice provides a probe  and requests access from the server. Armed with these notations, we first provide a functional definition of a Biometric Access Control system.
and requests access from the server. Armed with these notations, we first provide a functional definition of a Biometric Access Control system.
Definition 3.1.
A Biometric Access Control (BAC) system is a computational protocol between two parties, Bob with a biometric database  and Alice with a probe
and Alice with a probe  , such that at the end of the protocol, Alice and Bob can jointly compute the following value:
, such that at the end of the protocol, Alice and Bob can jointly compute the following value:

Adding user anonymity to a BAC system results in the following definition:
Definition 3.2.
An Anonymous BAC (ABAC) system is a BAC system on  and
and  with the following properties at the end of the protocol.
with the following properties at the end of the protocol.
(1)Except for the value  , Bob has negligible knowledge about
, Bob has negligible knowledge about  ,
,  , and the comparison results between
, and the comparison results between  and
and  for all
for all  .
.
(2)Except for the value  , Alice has negligible knowledge about
, Alice has negligible knowledge about  ,
,  ,
,  , and the comparison results between
, and the comparison results between  and
and  for all
for all  .
.
Like any other computationally secure protocols, "negligible knowledge" used in the above definition should be interpreted as, given the available information to a party, the distribution of all possible values of the private input from the other party is computationally indistinguishable from the uniformly random distribution [48]. The first property in Definition 3.2 defines the concept of user anonymity, that is, Bob knows nothing about Alice except whether her probe matches one or more biometric signals in  . As it has been demonstrated that even the distance values
. As it has been demonstrated that even the distance values  are sufficient for an attacker to recreate
are sufficient for an attacker to recreate  [49], the second property is designed to disclose the least amount of information to Alice.
[49], the second property is designed to disclose the least amount of information to Alice.
It is impossible to design a secure system without considering the possible adversarial behaviors from both parties. Adversarial behaviors are broadly classified into two types: semihonest and malicious. A dishonest party is called semihonest if he follows the protocol faithfully but attempts to find out about others' private data through the communication. A malicious party, on the other hand, will change private inputs or even disrupt the protocol by premature termination. Making the proposed system robust against a wide range of malicious behaviors is beyond the scope of this paper. Here, we assume Bob to be semihonest but allow certain malicious behaviors from Alice—we assume that Alice will engage in malicious behaviors only if those behaviors can increase her chance of gaining access, that is turning  into 1, from using a purely random probe. This is a restricted model because, for example, Alice will not prematurely terminate before Bob reaches the final step in computing
into 1, from using a purely random probe. This is a restricted model because, for example, Alice will not prematurely terminate before Bob reaches the final step in computing  . Also, Alice will not randomly modify any private input unless such modification will increase her chance of success.
. Also, Alice will not randomly modify any private input unless such modification will increase her chance of success.
In Section 5, we shall provide an implementation of an ABAC system on iris biometrics that is robust under the above security model. The procedure is based on repeated use of a homomorphic encryption system. An encryption system  is homomorphic with respect to an operation
is homomorphic with respect to an operation  in the plaintext domain if there exists another operator
in the plaintext domain if there exists another operator  in the ciphertext domain such that
in the ciphertext domain such that

In our system, we choose the Paillier encryption system as it is homomorphic over a large additive plaitext group and thus providing a wide dynamic range for computation. Given a plaintext number  , the Paillier encryption process is given as follows:
, the Paillier encryption process is given as follows:

where  is a product of two equal-length secret primes and
is a product of two equal-length secret primes and  is a random number in
is a random number in  to ensure semantic security. The public key
to ensure semantic security. The public key  consists of only
consists of only  . The decryption function
. The decryption function  with
with  and the secret key
and the secret key  being the Euler-phi function
being the Euler-phi function  is defined by the following two steps:
is defined by the following two steps:
(1)Compute  over the integer field;
over the integer field;
(2)
The Paillier system is secure under the decisional composite residuosity assumption and we refer interested readers to [50, Chapter 11], for details. Paillier is homomorphic over addition in  and the corresponding function is multiplication over the ciphertext field
and the corresponding function is multiplication over the ciphertext field  . We can also carry out multiplication with a known plaintext in the encrypted domain. These properties are summarized in:
. We can also carry out multiplication with a known plaintext in the encrypted domain. These properties are summarized in:

Multiplication with a number to which only the ciphertext is known can also be accomplished with a simple communication protocol. Assume that Bob wants to compute  based on the ciphertexts
based on the ciphertexts  and
and  . Alice has the secret key
. Alice has the secret key  but Bob wants to keep
but Bob wants to keep  ,
,  and
and  hidden from Alice. MULT
hidden from Alice. MULT (Protocol 1) is a secure protocol that can accomplish this task. It is secure because Alice can gain no knowledge about
(Protocol 1) is a secure protocol that can accomplish this task. It is secure because Alice can gain no knowledge about  and
and  from the uniformly random
from the uniformly random  and
and  where
where  and
and  are two random numbers generated by Bob, and Bob is never exposed to any plaintext related to
are two random numbers generated by Bob, and Bob is never exposed to any plaintext related to  and
and  . The complexities of MULT
. The complexities of MULT are three encryptions and seven encrypted-domain operations, (multiplication and exponentiation) on Bob side, as well as two decryptions and one encryption on Alice side. The communication costs are three encrypted numbers. The homomorphic properties and this protocol will be used extensively throughout this paper.
are three encryptions and seven encrypted-domain operations, (multiplication and exponentiation) on Bob side, as well as two decryptions and one encryption on Alice side. The communication costs are three encrypted numbers. The homomorphic properties and this protocol will be used extensively throughout this paper.
Protocol 1: Private multiplication MULT(Enc pk (x),Enc pk (y)).
Require: Bob:  ,
,  ; Alice:
; Alice: 
Ensure: Bob computes 
( ) Bob sends
) Bob sends  and
and 
to Alice where  and
and  are uniformly random numbers generated by Bob.
are uniformly random numbers generated by Bob.
( ) Alice decrypts
) Alice decrypts  and
and  , computes
, computes  and send
and send
it to Bob.
( ) Bob computes
) Bob computes  in the encrypted domain as follows:
in the encrypted domain as follows:

4. System Overview
In this section, we provide an overview of the entire design of our efficient anonymous biometric access control system. Again, we will use Bob and Alice to denote the biometric system owner and the user, respectively. The overall framework of our proposed system is shown in Figure 1. There are two main processing components in our systems: the preprocessing step and the matching step. While the matching step is executed for every probe, the preprocessing step is executed only once by Bob to compute a publiclyavailable quantization table based on a process called  -Anonymous Quantization. The purpose of the public table is that, based on a joint secure-index selection of the table entry between Alice and Bob, Bob can significantly reduce the scope of the similarity search from the entire database
-Anonymous Quantization. The purpose of the public table is that, based on a joint secure-index selection of the table entry between Alice and Bob, Bob can significantly reduce the scope of the similarity search from the entire database  to approximately
to approximately  candidates. The
candidates. The  -Anonymous Quantization guarantees that (
-Anonymous Quantization guarantees that ( ) if there is an entry in Bob's database that matches Alice's probe, this entry must be among these candidates, (
) if there is an entry in Bob's database that matches Alice's probe, this entry must be among these candidates, ( ) all the candidates are maximally dissimilar so as to provide the least amount information about Alice's probe, and (
) all the candidates are maximally dissimilar so as to provide the least amount information about Alice's probe, and ( ) the public table discloses no information about Bob's database. The details of the
) the public table discloses no information about Bob's database. The details of the  -Anonymous Quantization and the secure-index selection will be discussed in Section 6.
-Anonymous Quantization and the secure-index selection will be discussed in Section 6.

ABAC system overview.
After computing the proper quantization cell index from the public table, Bob identifies all the candidates and then engages with Alice in a joint secret matching process to determine if Alice's probe resembles any one of the candidates. This process is conducted in a multiparty computation and communication protocol between Alice and Bob based on Paillier homomorphic encryption. We assume that there is an open network between Bob and Alice that will guarantee message integrity. Since only encrypted content is exchanged, there is no need for any protection against eavesdroppers. For each session, Alice will be responsible for generating the private and public keys for the encryption and sharing the public key with Bob. In other words, a different set of keys will be used for each different user. Furthermore this protocol demands comparable computational capabilities from both parties. Thus it is imperative to use the preprocessing step to reduce the computational complexity of this matching step. As the secret matching utilizes all the fundamental processing blocks for the entire system, we will first explain this component in the following section.
5. Homomorphic Encryption-Based ABAC
In this section, we describe the implementation of an ABAC system on iris features using homomorphic encryption. The system consists of three main steps: distance computation, bit extraction, and secure comparison. Except for the first step of distance computation which is specific towards iris comparison, the remaining two steps and the overall protocol are general enough for other types of biometric features and similarity search. We shall follow a bottom-up approach by first describing individual components and demonstrating their safety before assembling them together as an ABAC system.
5.1. Hamming Distance
The modified Hamming distance  described in (2) is used to measure the dissimilarity between iris patterns
described in (2) is used to measure the dissimilarity between iris patterns  and
and  which are both 9600 bits long [51]. As the division in (2) may introduce floating point numbers, we focus on the following distance and roll the denominator into the similarity threshold during the later stage of comparison
which are both 9600 bits long [51]. As the division in (2) may introduce floating point numbers, we focus on the following distance and roll the denominator into the similarity threshold during the later stage of comparison

DIST (Protocol 2) provides a secure computation of the modified Hamming distances between Alice's probe q and Bob's  . Alice needs to provide the encryption of individual bits
. Alice needs to provide the encryption of individual bits  and their negation to Bob. Even though Bob can compute the negation in the encryption domain by performing
and their negation to Bob. Even though Bob can compute the negation in the encryption domain by performing  , it is computationally more efficient for Alice to compute them in plaintext as demonstrated in Section 7. In step
, it is computationally more efficient for Alice to compute them in plaintext as demonstrated in Section 7. In step  (a), Bob computes the XOR between each bit of the query and the corresponding bit in each record
(a), Bob computes the XOR between each bit of the query and the corresponding bit in each record  .
.  can then be computed by summing all the XOR results in the encrypted domain. Bob cannot derive any information about Alice's probe as the operations are all performed in the encrypted domain. Alice does not participate in this protocol at all. The complexity of DIST includes
can then be computed by summing all the XOR results in the encrypted domain. Bob cannot derive any information about Alice's probe as the operations are all performed in the encrypted domain. Alice does not participate in this protocol at all. The complexity of DIST includes  encrypted-domain operations where
encrypted-domain operations where  is the size of
is the size of  and
and  is the number of bits for each feature vector.
is the number of bits for each feature vector.
Protocol 2: Secure computation of distances DIST(DB, Enc
pk
( ), Enc
pk
(
), Enc
pk
( ) for
) for  .
.
Require: Bob:  for
for  ,
,  and
and  for
for 
Ensure: Bob computes  for
for  .
.
( ) For
) For  , Bob repeats the following two steps:
, Bob repeats the following two steps:
(a) For  , compute
, compute

(b) Compute

5.2. Bit Extraction
The next step is to compare the calculated encrypted distance with a plaintext threshold. As comparison cannot be expressed in terms of summation and multiplication of the two numbers, we need to first extract individual bits from the encrypted distance. EXTRACT (Protocol 3) is a secure protocol between Bob and Alice to extract individual encrypted bits
(Protocol 3) is a secure protocol between Bob and Alice to extract individual encrypted bits  for
for  from
from  , where
, where  is a
is a  -bit number. The idea is for Bob to ask Alice's assistance in decrypting the numbers and extracting the bits. To protect Alice from knowing anything about
-bit number. The idea is for Bob to ask Alice's assistance in decrypting the numbers and extracting the bits. To protect Alice from knowing anything about  , Bob sends
, Bob sends  to Alice who then extracts and encrypts individual bits
to Alice who then extracts and encrypts individual bits  . Except for the least significant bit (LSB), Bob cannot undo the randomization in
. Except for the least significant bit (LSB), Bob cannot undo the randomization in  by carrying out an XOR operation with the bits of
by carrying out an XOR operation with the bits of  due to the carry bits. To rectify this problem, step
due to the carry bits. To rectify this problem, step  (d) in EXTRACT zeros out the lower-order bits after they have been extracted and stores the intermediate result in
(d) in EXTRACT zeros out the lower-order bits after they have been extracted and stores the intermediate result in  , thus guaranteing the absence of any carry bits from the lower order bits during the randomization. Alice cannot learn any information about
, thus guaranteing the absence of any carry bits from the lower order bits during the randomization. Alice cannot learn any information about  because the bit to be extracted,
because the bit to be extracted,  , is uniformly distributed between 0 and 1. Plaintexts obtained by Alice in different iterations are also uncorrelated as a different random number is used by Bob in each iteration. Even though Alice wants to make
, is uniformly distributed between 0 and 1. Plaintexts obtained by Alice in different iterations are also uncorrelated as a different random number is used by Bob in each iteration. Even though Alice wants to make  as small as possible to pass the comparison test, there is no advantage of replacing her replies to Bob with any other value. Bob is not able to obtain any information about
as small as possible to pass the comparison test, there is no advantage of replacing her replies to Bob with any other value. Bob is not able to obtain any information about  either as all operations are performed in the encrypted domain. Based on the security model introduced in Section 3, this protocol is secure. The complexities of EXTRACT are
either as all operations are performed in the encrypted domain. Based on the security model introduced in Section 3, this protocol is secure. The complexities of EXTRACT are  encryptions and
encryptions and  encrypted-domain operation for Bob, as well as
encrypted-domain operation for Bob, as well as  decryptions and
decryptions and  encryptions for Alice. The communication costs are
encryptions for Alice. The communication costs are  encrypted numbers.
encrypted numbers.
Protocol 3: Bit extraction EXTRACT(Enc
pk
( )).
)).
Require: Bob:  where
where  is a
is a  -bit number; Alice
-bit number; Alice  .
.
Ensure: Bob computes  for
for  with
with  being the LSB.
being the LSB.
( ) Bob creates a temporary variable
) Bob creates a temporary variable  .
.
( ) For
) For  , the following steps are repeated
, the following steps are repeated
(a) Bob generates a random number  and sends
and sends  to Alice.
to Alice.
(b) Alice decrypts  , extracts the
, extracts the  bit
bit  and sends
and sends 
back to Bob.
(c) Bob computes  .
.
(d) Bob updates 
5.3. Threshold Comparison
Based on the encrypted bit representations of the distances, we can carry out the actual threshold comparison. COMPARE (Protocol 4) is based on the secure comparison protocol developed in [14]. Step
(Protocol 4) is based on the secure comparison protocol developed in [14]. Step  (a) accumulates the differences between the two numbers starting from the most significant bits. The state variable
(a) accumulates the differences between the two numbers starting from the most significant bits. The state variable  at the
at the  th step implies that the bits at order
th step implies that the bits at order  and higher between
and higher between  and
and  match perfectly with each other.
match perfectly with each other.  tep
tep  (b) then computes
(b) then computes  where
where  if and only if
if and only if  ,
,  , and
, and  . This implies that
. This implies that  . In other words,
. In other words,  is true if and only if there exists
is true if and only if there exists  . In the last step, we invoke the secure multiplication as described in Protocol 1 to combine all
. In the last step, we invoke the secure multiplication as described in Protocol 1 to combine all  together into
together into  which is the desired output. Bob gains no knowledge in this protocol as he never handles any plaintext data. The only step that Alice involves in is in the secure multiplication. The adversarial intention of Alice is to make
which is the desired output. Bob gains no knowledge in this protocol as he never handles any plaintext data. The only step that Alice involves in is in the secure multiplication. The adversarial intention of Alice is to make  zero so as to pass the comparison test. However, the randomization step in Protocol 1 provides no additional knowledge nor advantage for Alice to change her input. Thus, this protocol is secure. The complexities of COMPARE are
zero so as to pass the comparison test. However, the randomization step in Protocol 1 provides no additional knowledge nor advantage for Alice to change her input. Thus, this protocol is secure. The complexities of COMPARE are  encryptions and
encryptions and  encrypted-domain operations on Bob side, as well as
encrypted-domain operations on Bob side, as well as  decryptions and
decryptions and  encryptions on Alice side. The communication costs are
encryptions on Alice side. The communication costs are  encrypted numbers.
encrypted numbers.
Protocol 4: Secure comparison COMPARE(Enc
pk
( )
) .
.
Require Bob:  and
and  for
for  ; Alice:
; Alice: 
Ensure Bob computes  such that
such that  if
if  .
.
( ) Bob sets
) Bob sets  ,
,  .
.
( ) For
) For  starting from the MSB, Bob and Alice compute
starting from the MSB, Bob and Alice compute
(a) 
(b) 

(c)  .
.
5.4. Overall Algorithm
Protocol 5 defines the overall ABAC system. Steps  and
and  show that Alice first sends Bob her public key and the encrypted bits of her probe. Steps 3 and 4 use secure distance computation DIST (Protocol 2) and secure bit extraction EXTRACT (Protocol 3) to compute the encrypted bit representations of all the distances. Steps 4 and 5 then use secure comparison COMPARE (Protocol 4) and accumulate the results into
show that Alice first sends Bob her public key and the encrypted bits of her probe. Steps 3 and 4 use secure distance computation DIST (Protocol 2) and secure bit extraction EXTRACT (Protocol 3) to compute the encrypted bit representations of all the distances. Steps 4 and 5 then use secure comparison COMPARE (Protocol 4) and accumulate the results into  where
where  if and only if
if and only if  for some
for some  . To determine if Alice's probe produces a match, Bob cannot simply send Alice
. To determine if Alice's probe produces a match, Bob cannot simply send Alice  for decryption as she will simply returns a zero to gain access. Instead, Bob adds a random share
for decryption as she will simply returns a zero to gain access. Instead, Bob adds a random share  and sends
and sends  to Alice. The decrypted value
to Alice. The decrypted value  cannot be sent directly to Bob for him to compute
cannot be sent directly to Bob for him to compute  . Unless
. Unless  , the actual value of
, the actual value of  should not be disclosed to Bob in plaintext as it may disclose some information about the distance computations. Instead, we assume the existence of a Collision-Resistant Hash Function HASH to which Bob and Alice share the same key
should not be disclosed to Bob in plaintext as it may disclose some information about the distance computations. Instead, we assume the existence of a Collision-Resistant Hash Function HASH to which Bob and Alice share the same key  [50, Chapter 4]. Alice and Bob compute HASH
[50, Chapter 4]. Alice and Bob compute HASH and HASH
and HASH , respectively. As the hash function is collision resistant, their equality implies that
, respectively. As the hash function is collision resistant, their equality implies that  and Bob can verify that Alice's probe matches one of the entries in
and Bob can verify that Alice's probe matches one of the entries in  without knowing the actual value of the probe. Since Alice knows nothing about
without knowing the actual value of the probe. Since Alice knows nothing about  , she cannot cheat by sending a fake hash value. The complexities of Protocol 5 are
, she cannot cheat by sending a fake hash value. The complexities of Protocol 5 are  encryptions and
encryptions and  encrypted-domain operations for Bob, as well as
encrypted-domain operations for Bob, as well as  encryptions and decryptions for Alice. The communication costs are
encryptions and decryptions for Alice. The communication costs are  encrypted numbers.
encrypted numbers.
Protocol 5: ABAC(DB, q).
Require: Bob:  and
and  ; Alice:
; Alice: 
Ensure : Bob computes  if
if  for some
for some  and 0 otherwise
and 0 otherwise
( ) Alice sends
) Alice sends  to Bob.
to Bob.
( ) Alice computes
) Alice computes  and
and  for
for  and sends them to Bob.
and sends them to Bob.
( ) Bob executes DIST
) Bob executes DIST to obtain
to obtain
 for
for  .
.
( ) For
) For  , Bob and Alice execute EXTRACT
, Bob and Alice execute EXTRACT to obtain the
to obtain the
binary representations  for
for  .
.
( ) Bob sets
) Bob sets  .
.
( ) For
) For  , Bob and Alice computes
, Bob and Alice computes
(a)  for
for 

(b)  .
.
( ) Bob generates a random number
) Bob generates a random number  , computes
, computes  and sends Alice
and sends Alice  .
.
( ) Alice decrypts
) Alice decrypts  , computes
, computes  and sends it back to Bob.
and sends it back to Bob.
( ) Bob sets
) Bob sets  if HASH
if HASH =
=  and 0 otherwise.
and 0 otherwise.
6.  -Anonymous BAC
-Anonymous BAC
 -Anonymous BAC
-Anonymous BACIn Section 5, we show that both the complexities and the communication costs of the ABAC depend linearly on the size of the database, making ABAC difficult to scale to large databases. Inspired by the  -anonymity model, a simple approach is to tradeoff complexity with privacy by quickly narrowing Alice's query into a small group of
-anonymity model, a simple approach is to tradeoff complexity with privacy by quickly narrowing Alice's query into a small group of  candidates and then performing the full cryptographic search only on this small group.
candidates and then performing the full cryptographic search only on this small group.  will serve as a parameter to balance between the complexity and the privacy needed by Alice. This is the idea behind the
will serve as a parameter to balance between the complexity and the privacy needed by Alice. This is the idea behind the  -Anonymous Biometric Access Control system.
-Anonymous Biometric Access Control system.
Definition 6.1.
A  BAC (
BAC ( -ABAC) system is a BAC system on Bob's database
-ABAC) system is a BAC system on Bob's database  and Alice's probe
and Alice's probe  with the following properties at the end of the protocol.
with the following properties at the end of the protocol.
(1)There exists a subset  with
with  such that for all
such that for all  , Bob knows
, Bob knows  .
.
(2)Except for the value  as defined in Definition 3.1, Bob has negligible knowledge about
as defined in Definition 3.1, Bob has negligible knowledge about  and
and  , for all
, for all  , as well as the comparison results between
, as well as the comparison results between  and
and  for all
for all  .
.
(3)Except for the value  , Alice has negligible knowledge about
, Alice has negligible knowledge about  ,
,  ,
,  , and the comparison results between
, and the comparison results between  and
and  for all
for all  .
.
The definition of  -ABAC system is similar to that of ABAC except that Bob can prematurely exclude
-ABAC system is similar to that of ABAC except that Bob can prematurely exclude  from the comparison. Even though Alice may be aware of such a narrowing process, the
from the comparison. Even though Alice may be aware of such a narrowing process, the  -ABAC has the same restriction on Alice's knowledge about
-ABAC has the same restriction on Alice's knowledge about  as the regular ABAC. There are two challenges in designing a
as the regular ABAC. There are two challenges in designing a  -ABAC system.
-ABAC system.
(1)How do we find  so that the process will disclose as little information as possible about
so that the process will disclose as little information as possible about  to Bob?
to Bob?
(2)How can Alice choose  that contains the element that is close to
that contains the element that is close to  without learning anything about
without learning anything about  ?
?
Sections 6.1 and 6.2 describe our approaches in solving these problems in the context of iris matching.
6.1. k-Anonymous Quantization
A direct consequence of Definition 6.1 is that if there exists an  such that
such that  ,
,  must be in
must be in  . In order to achieve the goal of complexity reduction, our approach is to devise a static quantization scheme of the feature space
. In order to achieve the goal of complexity reduction, our approach is to devise a static quantization scheme of the feature space  and publish it in a scrambled form so that Alice can select the right group on her own. To explain this scheme, let us start with the definition of a
and publish it in a scrambled form so that Alice can select the right group on her own. To explain this scheme, let us start with the definition of a  -ball
-ball  -quantization. Define
-quantization. Define  or the
or the  -ball of
-ball of  to be the smallest subset of
to be the smallest subset of  that contains all
that contains all  with
with  . An
. An  -ball
-ball  -quantization of
-quantization of  is defined below.
is defined below.
Definition 6.2.
An  -ball
-ball -quantization (eBkQ) of
-quantization (eBkQ) of  is a partition
is a partition  of
of  with the following properties:
with the following properties:
(1) and
and  for
for  ,
,
(2)For all  ,
,  or
or  for
for  ,
,
(3) for
for  .
.
Property  of Definition 6.2 ensures that
of Definition 6.2 ensures that  is a partition while property 2 ensures that no
is a partition while property 2 ensures that no  -ball centered at a data point straddles two cells. The last property ensures that each cell must at least contain
-ball centered at a data point straddles two cells. The last property ensures that each cell must at least contain  elements from
elements from  . The importance of using an eBkQ
. The importance of using an eBkQ  is that if
is that if  is a shared knowledge between Alice and Bob, Alice can select
is a shared knowledge between Alice and Bob, Alice can select  and communicate the cell index
and communicate the cell index to Bob. Then Bob can compute
to Bob. Then Bob can compute  which must contain, if exists, any
which must contain, if exists, any  where
where  .
.
While a typical vector quantization of  will satisfy the
will satisfy the  -ball preserving criteria, the requirement of preserving the anonymity of
-ball preserving criteria, the requirement of preserving the anonymity of  imposes a very different constraint. Specifically, we would like all the data points in
imposes a very different constraint. Specifically, we would like all the data points in  to be maximally dissimilar so that no common traits can be learned from
to be maximally dissimilar so that no common traits can be learned from  . This leads to our definition of
. This leads to our definition of  -Anonymous Quantization (kAQ).
-Anonymous Quantization (kAQ).
Definition 6.3.
An optimal -anonymous quantization
-anonymous quantization is an eBkQ of
is an eBkQ of  that maximizes the following utility function among all possible eBkQ
that maximizes the following utility function among all possible eBkQ  :
:

The utility function (10) can be interpreted as the total dissimilarity of the most homogeneous cell  in the partition. The utility function also depends on the number of data points in a cell—adding a new point to an existing cell will always increase its utility. Thus finding the partition that maximizes this utility function not only can ensure the minimal amount of dissimilarity within a cell, but also can promotes equal distribution of data points among different cells. Given a fixed number of cells, it is important to minimize the variation in the number of data points among different cells so that the computational complexities of the encrypted-domain matching in different cells would be comparable.
in the partition. The utility function also depends on the number of data points in a cell—adding a new point to an existing cell will always increase its utility. Thus finding the partition that maximizes this utility function not only can ensure the minimal amount of dissimilarity within a cell, but also can promotes equal distribution of data points among different cells. Given a fixed number of cells, it is important to minimize the variation in the number of data points among different cells so that the computational complexities of the encrypted-domain matching in different cells would be comparable.
It is challenging to solve for the optimal kAQ for the iris matching problem due to the high dimension, 9600 to be exact, and the uncommon distance used. Our first step is to project this high-dimensional space into a lower-dimensional Euclidean space  by using Fastmap followed by PCA. The Fastmap is used to embed the native geometry of the feature space into an Euclidean space while the PCA optimally minimizes the dimension of the resulting space. Even in this lower-dimensional space, the structure of a quantization, namely, the boundary of individual cells, can still be difficult to specify. To approximate the boundary with a compact representation, we first use a simple uniform lattice quantization to partition
by using Fastmap followed by PCA. The Fastmap is used to embed the native geometry of the feature space into an Euclidean space while the PCA optimally minimizes the dimension of the resulting space. Even in this lower-dimensional space, the structure of a quantization, namely, the boundary of individual cells, can still be difficult to specify. To approximate the boundary with a compact representation, we first use a simple uniform lattice quantization to partition  into a rectilinear grid
into a rectilinear grid  consisting of
consisting of  bins
bins  . Then, we maximize the utility function (10) but force the cell boundary to be along those of the bins. This turns an optimal partitioning problem in continuous space into a discrete knapsack problem in assigning bins to cells through a mapping function
. Then, we maximize the utility function (10) but force the cell boundary to be along those of the bins. This turns an optimal partitioning problem in continuous space into a discrete knapsack problem in assigning bins to cells through a mapping function  to optimize the utility function. The process is described in Figure 2. We denote the resulting approximated
to optimize the utility function. The process is described in Figure 2. We denote the resulting approximated  -quantization as
-quantization as  .
.

Approximation of the quantization boundary (a) along the bins (b). The number of bins  here is 3. There are also two bins that are present in both cells.
here is 3. There are also two bins that are present in both cells.
As the utility function (10) is based on individual data points, a bin containing multiple  -balls may present in multiple cells. As such,
-balls may present in multiple cells. As such,  is no longer a true partition and the mapping function
is no longer a true partition and the mapping function  is a multivalued function. A probe falling in these "overlapped" bins will invoke multiple cells, resulting in a larger candidate set
is a multivalued function. A probe falling in these "overlapped" bins will invoke multiple cells, resulting in a larger candidate set  . Two examples of such overlapped bins are shown in Figure 2. This increases computational complexity and as such, it is important to minimize the amount of overlap. Due to the uneven distribution of data points in the feature space, a global
. Two examples of such overlapped bins are shown in Figure 2. This increases computational complexity and as such, it is important to minimize the amount of overlap. Due to the uneven distribution of data points in the feature space, a global  can inflate the size of balls in some area of the feature space resulting in significant overlap problems. In our implementation, we do not use
can inflate the size of balls in some area of the feature space resulting in significant overlap problems. In our implementation, we do not use  balls but estimate the local similarity structure by using multiple similar feature vectors from each iris, and creating a "bounding box" which is the smallest rectilinear box along the bin boundaries that encloses all the bins containing these similar feature vectors. If any bin in a bounding box is assigned to cell
balls but estimate the local similarity structure by using multiple similar feature vectors from each iris, and creating a "bounding box" which is the smallest rectilinear box along the bin boundaries that encloses all the bins containing these similar feature vectors. If any bin in a bounding box is assigned to cell  , all the bins in the bounding box will have an assignment of cell
, all the bins in the bounding box will have an assignment of cell  .
.
Protocol 6 (KAQ) describes a greedy algorithm that computes a suboptimized  -anonymous quantization mapping function from the data. Step
-anonymous quantization mapping function from the data. Step  of KAQ sets the number of cells to be the maximum and the protocol will graduately decrease it until each cell has more than
of KAQ sets the number of cells to be the maximum and the protocol will graduately decrease it until each cell has more than  data points. The initialization steps in
data points. The initialization steps in  and
and  randomly assign a bounding box into each cell. Step
randomly assign a bounding box into each cell. Step  identifies the cells that have the minimum utility. Among these cells, steps
identifies the cells that have the minimum utility. Among these cells, steps  and
and  identify the cell
identify the cell  and the bounding box
and the bounding box  which together produce the maximum gain in utility. The bins inside
which together produce the maximum gain in utility. The bins inside  are then added to
are then added to  and the whole process repeats. This update not only provides a greedy maximization of the overall utility function but also has the tendency to produce an even distribution of data points among different cells. A newly updated cell will have a much lower chance of being updated again as it has a higher utility than others. The final step checks to see if any one cell has less than
and the whole process repeats. This update not only provides a greedy maximization of the overall utility function but also has the tendency to produce an even distribution of data points among different cells. A newly updated cell will have a much lower chance of being updated again as it has a higher utility than others. The final step checks to see if any one cell has less than  elements and, if yes, restarts the process with fewer target number of cells. For a fixed target number of cells, the complexity of this greedy algorithm is
elements and, if yes, restarts the process with fewer target number of cells. For a fixed target number of cells, the complexity of this greedy algorithm is  where
where  is the size of
is the size of  . It is important to point out that the output mapping
. It is important to point out that the output mapping  only contains entries of bins that belong to at least one bounding box.
only contains entries of bins that belong to at least one bounding box.
Protocol 6: Greedy k-anonymous quantization KAQ.
Require Bob: Projection of DB into  or
or  ; Bin and bounding box
; Bin and bounding box
structures in  ;
;
Ensure Bob computes the multi-valued mapping  that defines the cell
that defines the cell
membership of each bin.
( ) Set the initial number of cells
) Set the initial number of cells  .
.
( ) Let
) Let  the list of bounding boxes in
the list of bounding boxes in 
( ) Random initialization of cells: for
) Random initialization of cells: for  ,
,
(a) Randomly remove a bounding box  from
from  .
.
(b) Set  BB
BB .
.
( ) Identify the collection of cells
) Identify the collection of cells  with the lowest utility, that is,
with the lowest utility, that is,

where  contains all the bins in cell
contains all the bins in cell  .
.
( ) For each cell
) For each cell  in
in  , identify the bounding box
, identify the bounding box  that maximizes the utility of
that maximizes the utility of
cell  after adding
after adding  to it and denote the resulting utility as
to it and denote the resulting utility as  , that is,
, that is,


( ) Given
) Given  , identify the bounding box
, identify the bounding box  and cell
and cell  that give
that give
rise to the maximum gain of utility from step  .
.
( ) Set
) Set  and remove
and remove  from
from  .
.
( ) Go back to
) Go back to  tep
tep  until
until  is empty.
is empty.
( ) For
) For  , ensure that
, ensure that  . If not, set
. If not, set  and go
and go
back to step  .
.
6.2. Secure Index Selection
Let us first describe how Alice and Bob can jointly compute the projection of Alice's probe  into the lower-dimensional space formed by Fastmap and PCA. The projection needs to be performed in encrypted domain so that Alice does not reveal anything about her probe and Bob does not reveal any information about his database, the Fastmap pivot points and the PCA basis vectors. Note that the need for encrypted-domain processing does not affect the scalability of our system as the computation complexity depends only on the dimension of the feature space but not on the size of the database.
into the lower-dimensional space formed by Fastmap and PCA. The projection needs to be performed in encrypted domain so that Alice does not reveal anything about her probe and Bob does not reveal any information about his database, the Fastmap pivot points and the PCA basis vectors. Note that the need for encrypted-domain processing does not affect the scalability of our system as the computation complexity depends only on the dimension of the feature space but not on the size of the database.
The Fastmap projection in (3) involves a floating point division. The typical approach of premultiplying both sides by the divisor to ensure that integer-domain computation does not work. As the Fastmap update (4) needs to square the projection, recursive computation into higher dimensions will lead to a blowup in the dynamic range. To ensure all the computations are performed within in a fixed dynamic range, Alice and Bob need to agree on a predefined scaling factor  and rounding will be performed at each iteration of the Fastmap calculation. Specifically, given the encrypted probe
and rounding will be performed at each iteration of the Fastmap calculation. Specifically, given the encrypted probe  , Bob approximates the first projection
, Bob approximates the first projection  in encrypted domain based on the following formula derived from (3):
in encrypted domain based on the following formula derived from (3):

where  ,
,  ,
,  , and
, and  . All the multipliers on the right-hand side of (11) are known to Bob in plaintext and the distances can be computed in the encrypted domain using Procedure 2. Since rounding is involved,
. All the multipliers on the right-hand side of (11) are known to Bob in plaintext and the distances can be computed in the encrypted domain using Procedure 2. Since rounding is involved,  is just an approximation of
is just an approximation of  as computed with in the original Fastmap formula (3). Based on the computed encrypted values of
as computed with in the original Fastmap formula (3). Based on the computed encrypted values of  from the probe and
from the probe and  from a data point, the update (4) is executed as follows:
from a data point, the update (4) is executed as follows:

Bob again can compute the right-hand side of (12) entirely in encryption domain, with the square in the second term computed using Procedure 1. The value  is again approximated due to the rounding of the coefficient. Note that the left-hand side has an extra factor of
is again approximated due to the rounding of the coefficient. Note that the left-hand side has an extra factor of  which needs to be removed so as to prevent a blowup in the dynamic range. To accomplish that, Bob computes
which needs to be removed so as to prevent a blowup in the dynamic range. To accomplish that, Bob computes  where
where  is a random number, and sends the result to Alice. Alice decrypts it, divides it by
is a random number, and sends the result to Alice. Alice decrypts it, divides it by  , and rounds it to obtain
, and rounds it to obtain  . Alice encrypts the result and sends it back to Bob who will then remove the random number
. Alice encrypts the result and sends it back to Bob who will then remove the random number  .
.
Bob can now use the new distances to project the probe along the second pair of pivot objects  and
and  as follows:
as follows:

where  can be computed by Bob in plaintext. The extra factor of
can be computed by Bob in plaintext. The extra factor of  on the left-hand side of (13) can be removed with the help of Alice using a similar approach as previously discussed. As the iteration continues, the deviation of the rounded projection and the original projection will grow as the rounding error accumulates. However, the new distance computed at each iteration absorbs the rounding error from the previous projection. As a result, the distance in the projected space will approach the underlying distance in a similar manner as the original projection.
on the left-hand side of (13) can be removed with the help of Alice using a similar approach as previously discussed. As the iteration continues, the deviation of the rounded projection and the original projection will grow as the rounding error accumulates. However, the new distance computed at each iteration absorbs the rounding error from the previous projection. As a result, the distance in the projected space will approach the underlying distance in a similar manner as the original projection.
In the computation of PCA projection, we scale each basis vector with a large enough multiplier not only to absorb the fractional parts of the basis vector but also the scalar  used in Fastmap. Let the i th basis vector of PCA be
used in Fastmap. Let the i th basis vector of PCA be  where
where  with
with  being the target PCA dimension. The encrypted-domain PCA projection of the Fastmap projection of
being the target PCA dimension. The encrypted-domain PCA projection of the Fastmap projection of  can be computed as follows:
can be computed as follows:

The scalar  is selected so that the loss of precision due to rounding is sufficiently small.
is selected so that the loss of precision due to rounding is sufficiently small.
The last step of the process is to quantize the projection  . We only consider the quantization step size in powers of two so that the quantization process can be performed in the encrypted domain. First, we use the secure bit extraction routine EXTRACT to compute the binary representation of
. We only consider the quantization step size in powers of two so that the quantization process can be performed in the encrypted domain. First, we use the secure bit extraction routine EXTRACT to compute the binary representation of  . Then, we drop the lower order bits based on the chosen stepsize. The resulting bits are recombined to form the binary representation to the encrypted bin index
. Then, we drop the lower order bits based on the chosen stepsize. The resulting bits are recombined to form the binary representation to the encrypted bin index  .
.
In order to obtain the cell index  , we need an additional cryptographic tool: a homomorphic collision-resistant hash function
, we need an additional cryptographic tool: a homomorphic collision-resistant hash function  with the following homomorphic property [52, 53]:
with the following homomorphic property [52, 53]:

Our implementation is based on [52]. Bob generates both the public key  and the secret key for this hash function and shares the public key with Alice. Instead of directly publishing the mapping
and the secret key for this hash function and shares the public key with Alice. Instead of directly publishing the mapping  between the bin index and the corresponding cell indices, Bob publishes an obfuscated mapping
between the bin index and the corresponding cell indices, Bob publishes an obfuscated mapping  such that
such that  . The hash function sufficiently scrambles all the bin indices so that the distribution of Bob's data among all the bins classified in the KAQ algorithm is disguised as random sampling in the range of the hash function. To prevent Alice from launching a dictionary attack on the table, the length of the bin index must be large enough. This can be accomplished, for example, by padding random projections of the query to make the bin index longer. The cell indices will be published without any obfuscation—little information is leaked through them as it is shared knowledge between Alice and Bob that there are roughly
. The hash function sufficiently scrambles all the bin indices so that the distribution of Bob's data among all the bins classified in the KAQ algorithm is disguised as random sampling in the range of the hash function. To prevent Alice from launching a dictionary attack on the table, the length of the bin index must be large enough. This can be accomplished, for example, by padding random projections of the query to make the bin index longer. The cell indices will be published without any obfuscation—little information is leaked through them as it is shared knowledge between Alice and Bob that there are roughly  distinct cell indices, each of them occurring around
distinct cell indices, each of them occurring around  times.
times.
The reason behind why we need the homomorphic property (15) is to help Alice in computing  . After Bob finishes the computation of
. After Bob finishes the computation of  , he picks a random
, he picks a random  , computes
, computes  and
and  , and sends them to Alice. Alice then decrypts
, and sends them to Alice. Alice then decrypts  , computes
, computes  , and uses the homomorphic property to compute
, and uses the homomorphic property to compute  . After that, Alice performs a table lookup to find
. After that, Alice performs a table lookup to find  . If there are multiple cell indices in
. If there are multiple cell indices in  , Alice should not send all of them to Bob because he may use this information to significantly reduce the possible choices of
, Alice should not send all of them to Bob because he may use this information to significantly reduce the possible choices of  as overlapped bins are rare. Instead, Alice should send one cell index first. Then, she re-encrypts her probe and reruns the entire dimension reduction and index selection process as if she was a different user. The same
as overlapped bins are rare. Instead, Alice should send one cell index first. Then, she re-encrypts her probe and reruns the entire dimension reduction and index selection process as if she was a different user. The same  will be computed and Alice sends Bob the second index. The whole process is repeated until all the cell indices in
will be computed and Alice sends Bob the second index. The whole process is repeated until all the cell indices in  are exhausted or a match occurs.
are exhausted or a match occurs.
SELECT (Protocol 7) summarizes the above process on how Bob can identify the cell to which  belongs. As for the security of Protocol 7, steps
belongs. As for the security of Protocol 7, steps  through
through  are processing in encrypted domain and thus reveal no secrets to either parties. Steps
are processing in encrypted domain and thus reveal no secrets to either parties. Steps  and
and  allow Bob to identify the cell indices to which
allow Bob to identify the cell indices to which  belongs. As we assume Bob to be semihonest, Bob will not deviate from the protocol by adding any identifiable information to the public table
belongs. As we assume Bob to be semihonest, Bob will not deviate from the protocol by adding any identifiable information to the public table  . Alice has no incentive to deviate from this protocol as a wrong cell index will erase any chance of success in the subsequent encrypted-domain matching with the elements in the cell. The complexities of Protocol 7 are
. Alice has no incentive to deviate from this protocol as a wrong cell index will erase any chance of success in the subsequent encrypted-domain matching with the elements in the cell. The complexities of Protocol 7 are  on Bob side and
on Bob side and  on Alice side, where
on Alice side, where  is the Fastmap dimension,
is the Fastmap dimension,  is the PCA dimension, and
is the PCA dimension, and  is the bit length of the scaled PCA coordinates. The communication costs are
is the bit length of the scaled PCA coordinates. The communication costs are  encrypted numbers.
encrypted numbers.
Protocol 7: Secure cell index selection SELECT.
Require Alice: Probe  ; Bob: Fastmap pivot objects, PCA basis, and quantization step-size in
; Bob: Fastmap pivot objects, PCA basis, and quantization step-size in
PCA space,  ; Public: Scrambled Mapping
; Public: Scrambled Mapping  , Deterministic homomorphic
, Deterministic homomorphic
cipher with unknown secret key 
Ensure Bob gets  where
where  contains
contains 
( ) Alice and Bob computes
) Alice and Bob computes  for
for  .
.
( ) Bob creates an empty list
) Bob creates an empty list  .
.
( ) Quantization of the projection: for
) Quantization of the projection: for  ,
,
(a) Bob and Alice execute  EXTRACT
EXTRACT to get the encrypted
to get the encrypted
binary representation of the ith dimension of the projection of  .
.
(b) Bob discards  lower order encrypted bits from
lower order encrypted bits from  and add the remaining bits to the
and add the remaining bits to the
set  .
.
( ) Bob recombines individual encrypted bits in
) Bob recombines individual encrypted bits in  to create a single encrypted
to create a single encrypted  .
.
( ) Bob generates a random number
) Bob generates a random number  , compute and sends Alice
, compute and sends Alice  and
and  .
.
( ) Alice decrypts
) Alice decrypts  , computes
, computes  and uses it look
and uses it look
up the cell indices  .
.
( ) If
) If  has multiple cell indices, Alice will send the first one to Bob, wait for a random
has multiple cell indices, Alice will send the first one to Bob, wait for a random
amount of time, re-execute this entire procedure, and sends the second cell index. The
process is repeated until all cell indices in  are exhausted or a match occurs.
are exhausted or a match occurs.
7. Experiments and Discussions
For our experiments, we use the CASIA Iris database from the Chinese Academy of Sciences Institute of Automation (CASIA) [54], a common benchmark for evaluating the performance of iris recognition systems. For the iris feature extraction, we use the MATLAB code from [51] to generate both the iris feature vectors and the masks. Each iris feature vector is 9600 bit long. The similarity threshold  is set to be 0.35. We select 1948 samples from CASIA based on the following criteria: the distances are smaller than 0.35 between any two samples from the same eye, and larger than 0.40 between any two samples from different eyes. Furthermore, each eye contains at least six good samples and one sample is set aside for testing. A total of 160 individuals are included in our dataset. Our Paillier implementation is based on the Paillier Library developed by J Bethencourt [55]. The key length of the Paillier cipher is set to be 1024 bit which results in 2048-bit ciphertexts.
is set to be 0.35. We select 1948 samples from CASIA based on the following criteria: the distances are smaller than 0.35 between any two samples from the same eye, and larger than 0.40 between any two samples from different eyes. Furthermore, each eye contains at least six good samples and one sample is set aside for testing. A total of 160 individuals are included in our dataset. Our Paillier implementation is based on the Paillier Library developed by J Bethencourt [55]. The key length of the Paillier cipher is set to be 1024 bit which results in 2048-bit ciphertexts.
7.1. Encrypted Domain Processing
In this subsection, we summarize the complexity and communication costs of various encrypted-domain processes discussed in this paper. The communication cost is measured based on total amount of information exchanged between Bob and Alice without any overhead from the network stack. The computation time excludes networking time and is computed based on averaging 100 trials. All of them are implemented in C language on a Linux machine with a 2.4 GHz AMD Athlon 64 CPU and 2 GB memory. Table 1 summarizes the results. Encrypted-domain addition and multiplication with plaintext are relatively lightweight, except when the plaintext multiplier is negative (i.e., a large positive number in modular arithmetic). Multiplication between two encrypted numbers (MULT) takes the longest and requires information exchange between Bob and Alice. Hamming distance (DIST) is fast as there are no encryption or decryption. Bit extraction (EXTRACT) takes longer and threshold comparison (COMPARE) takes the longest due to the repeated use of negative numbers, encryption and decryption processes. The long computation time for Query preparation is primarily due the high dimension of the iris feature. The overall computation of an ABAC system consists of a fixed setup time of query preparation followed by the time taken for the remaining steps scaled by the size of the database. For a database of 10000 iris, our ABAC system is estimated to take 41,490 seconds or 11.5 hours and 120 MBytes of network bandwidth. On the other hand, in a  -anonymous ABAC system, the fixed setup time is the Query Preparation and the SELECT process. The matching complexity depends only on
-anonymous ABAC system, the fixed setup time is the Query Preparation and the SELECT process. The matching complexity depends only on  but not on the size of the database, except for the rare cases in which the probe falls into an overlapped bin. We shall study the effect of the quantization on the number of overlapped bins in details in Section 7.2. Apart from these exceptions, for the same database of 10000 iris patterns using a
but not on the size of the database, except for the rare cases in which the probe falls into an overlapped bin. We shall study the effect of the quantization on the number of overlapped bins in details in Section 7.2. Apart from these exceptions, for the same database of 10000 iris patterns using a  -ABAC system with
-ABAC system with  , the time required is only 650 seconds and the bandwidth is 1.3 MBytes.
, the time required is only 650 seconds and the bandwidth is 1.3 MBytes.
7.2. k-Anonymous Quantization
In the  -ABAC system, we first use Fastmap to reduce the original 9600-bits iris code into 100-dimension Euclidean space. Then we use PCA again to further reduce the dimension. Two PCA dimensions, 10 and 20, are tested in our experiments. These steps were performed on a machine running Windows XP Pro. with 3.4 GHz Intel Pentium 4 CPU and 2 GB of RAM. The rum times for Fastmap and PCA are 36.24 and 0.274 seconds. There is a loss in performance in each step of projection as the distances cannot be represented as accurately. The plots of False Accept Rates (FAR) versus False Reject Rate (FRR) for the original space and the two projected cases are shown in Figure 3. The performance clearly declines as the dimension decreases from 20 to 10. The consequence of dimension reduction is that the similarity structure cannot be well approximated in low dimensions. In defining the
-ABAC system, we first use Fastmap to reduce the original 9600-bits iris code into 100-dimension Euclidean space. Then we use PCA again to further reduce the dimension. Two PCA dimensions, 10 and 20, are tested in our experiments. These steps were performed on a machine running Windows XP Pro. with 3.4 GHz Intel Pentium 4 CPU and 2 GB of RAM. The rum times for Fastmap and PCA are 36.24 and 0.274 seconds. There is a loss in performance in each step of projection as the distances cannot be represented as accurately. The plots of False Accept Rates (FAR) versus False Reject Rate (FRR) for the original space and the two projected cases are shown in Figure 3. The performance clearly declines as the dimension decreases from 20 to 10. The consequence of dimension reduction is that the similarity structure cannot be well approximated in low dimensions. In defining the  -Anonymous quantization, we rely on a uniform quantization grid and similarity within a single iris is estimated based on a bounding box of similar features. If the similarity structure is poorly represented, bounding boxes begin to overlap. Probe falling in overlapped areas may need to invoke multiple cells, and thus increase the computational complexities. Figure 4 shows the histogram of the fraction of bins that overlap different numbers of bounding boxes. For
-Anonymous quantization, we rely on a uniform quantization grid and similarity within a single iris is estimated based on a bounding box of similar features. If the similarity structure is poorly represented, bounding boxes begin to overlap. Probe falling in overlapped areas may need to invoke multiple cells, and thus increase the computational complexities. Figure 4 shows the histogram of the fraction of bins that overlap different numbers of bounding boxes. For  , 88
, 88 of the bins are contained in only one bounding box and 96
of the bins are contained in only one bounding box and 96 in at most two bounding boxes. When the dimension is reduced to
in at most two bounding boxes. When the dimension is reduced to  , these numbers reduce to 55
, these numbers reduce to 55 and 76
and 76 . Even though overlapped bins are not necessarily classified into different cells by the KAQ algorithm, their total number serves as the upper bound of bins with multiple cell affiliations.
. Even though overlapped bins are not necessarily classified into different cells by the KAQ algorithm, their total number serves as the upper bound of bins with multiple cell affiliations.

FRR versus FAR for using (a) the original feature space, (b) 100
 Fastmap and then
Fastmap and then
 dimensional PCA, and (c) 100d Fastmap and then
dimensional PCA, and (c) 100d Fastmap and then
 dimensional PCA.
dimensional PCA.

Histogram of overlapped bins.
Next, we consider the performance of KAQ. This algorithm, programmed in C language, was run on a machine running Windows XP Pro. with 2.0 GHz AMD Athlon 64 CPU and 1 GB of RAM. The execution time is a function of the size of the database and takes less than 2 milliseconds to complete regardless of the parameters we used. We have tested the algorithms for various values of  and for
and for  and
and  dimensions. Table 2 summarizes the outputs of the KAQ algorithm at
dimensions. Table 2 summarizes the outputs of the KAQ algorithm at  . The first column shows the input parameter
. The first column shows the input parameter  . The second column shows the average and standard deviation of the number of data points in each cell.
. The second column shows the average and standard deviation of the number of data points in each cell.  is the lower bound of the cell size and KAQ manages to produce consistent cell sizes with small variance. The third column shows the utility function as defined in (10) which measures the minimum level of privacy among all the cells. The fourth column considers the average utility function and its standard deviation over all the cells. Again, the standard deviations are generally very small demonstrating the consistency across different cells. The utility increases with
is the lower bound of the cell size and KAQ manages to produce consistent cell sizes with small variance. The third column shows the utility function as defined in (10) which measures the minimum level of privacy among all the cells. The fourth column considers the average utility function and its standard deviation over all the cells. Again, the standard deviations are generally very small demonstrating the consistency across different cells. The utility increases with  as the bigger the
as the bigger the  is, the more data points are grouped into the same cell. On the other hand, neither the cell size nor
is, the more data points are grouped into the same cell. On the other hand, neither the cell size nor  is reliable metrics of complexity as they do not take the overlapping among cells into consideration. To provide a more realistic measure, we hold back one data point per individual iris during the quantization construction and use them to test the true complexity. Specifically, we measure complexity based on the actual number of data points in the union of cells that contains the testing probe. The results are tabulated in the last column. The complexity number will be larger than the cell size if the probe falls into a bin that overlaps more than one cell and the number of data points will at least double. The quantized increase in the number of cells accounts for the large standard deviation. In general, the complexity is roughly 1.5 times that of the average cell size.
is reliable metrics of complexity as they do not take the overlapping among cells into consideration. To provide a more realistic measure, we hold back one data point per individual iris during the quantization construction and use them to test the true complexity. Specifically, we measure complexity based on the actual number of data points in the union of cells that contains the testing probe. The results are tabulated in the last column. The complexity number will be larger than the cell size if the probe falls into a bin that overlaps more than one cell and the number of data points will at least double. The quantized increase in the number of cells accounts for the large standard deviation. In general, the complexity is roughly 1.5 times that of the average cell size.
Table 3 summarizes the results for KAQ  . While showing a similar trend as Table 2, there are a number of major differences. All the measurements show a much higher level of noise as compared with the previous experiments. This is due to the significant amount of overlapping among bounding boxes. Thus, even when the KAQ algorithm tries to evenly spread the data points, the overlapping forces bounding boxes to be in many cells at the same time. As a consequence, the complexity numbers are much higher than those from KAQ at
. While showing a similar trend as Table 2, there are a number of major differences. All the measurements show a much higher level of noise as compared with the previous experiments. This is due to the significant amount of overlapping among bounding boxes. Thus, even when the KAQ algorithm tries to evenly spread the data points, the overlapping forces bounding boxes to be in many cells at the same time. As a consequence, the complexity numbers are much higher than those from KAQ at  . The utility numbers also decrease from before as the distance measurements are not as well preserved.
. The utility numbers also decrease from before as the distance measurements are not as well preserved.
As there are no comparable quantization schemes in the literature for maximizing privacy, we have chosen, as a reference scheme, random cell assignment for each bounding box at a target number of cells. We call this scheme RANDOM and it is a sensible choice for ensuring individuals with similar iris features to be grouped at a random manner. The testing methodology is that we would first run the KAQ algorithm approach for a specific  , and then use the same number of cells for RANDOM. Ten random trials of RANDOM are run at each operating point. The results for
, and then use the same number of cells for RANDOM. Ten random trials of RANDOM are run at each operating point. The results for  are summarized in Table 4. As expected, RANDOM shows a significant drop in utility as no explicit optimization mechanism is used. The complexity numbers are comparable to those of KAQ as they are mostly a function of the geometry of the data distribution which dictates the overlapping of the bounding boxes.
are summarized in Table 4. As expected, RANDOM shows a significant drop in utility as no explicit optimization mechanism is used. The complexity numbers are comparable to those of KAQ as they are mostly a function of the geometry of the data distribution which dictates the overlapping of the bounding boxes.
We finally present the idea of trading off complexities with privacy, as measured by the utility function. We plot the complexity versus utility for all the three schemes in Figure 5. We have left out the error bars as the standard deviation for the complexity numbers is not meaningful due to the quantized effect of cell increase. This figure demonstrates that the KAQ algorithm provides a good level of privacy protection as the curves for both dimension reside on the high end of utility. While KAQ at  does not scale well when a high level of privacy is needed, KAQ at
does not scale well when a high level of privacy is needed, KAQ at  stays relatively linear. RANDOM is not able to offer much privacy protection.
stays relatively linear. RANDOM is not able to offer much privacy protection.

Tradeoff between complexity and utility (privacy).
8. Conclusions
In this paper, we have proposed a design for the Anonymous Biometric Control System (ABAC) which allows a biometric server to verify the membership status of a user without knowing his/her identity. The system is composed of various secure multiparty protocols including Hamming distance computation, bit extraction, comparison and result aggregation, all implemented with a homomorphic cipher. To reduce the computational and communication complexities of such a system, we have proposed a framework called the  -Anonymous ABAC system that tradeoffs privacy and complexity by quantizing the search space into cells, each of which contains at least
-Anonymous ABAC system that tradeoffs privacy and complexity by quantizing the search space into cells, each of which contains at least  members. Complexity is reduced by restricting the encrypted domain search process to a small number of cells. Privacy is measured by the dissimilarity of the smallest cell. A greedy quantization scheme on a reduced-dimensional space called
members. Complexity is reduced by restricting the encrypted domain search process to a small number of cells. Privacy is measured by the dissimilarity of the smallest cell. A greedy quantization scheme on a reduced-dimensional space called  -Anonymous Quantization has been devised to derive the optimal quantization that maximizes privacy. Secure procedures have been proposed to perform the dimensional reduction and cell lookup. Experimental results on a dataset of iris patterns demonstrate the effectiveness of our techniques in terms of balancing privacy and computational costs. We are currently investigating the extension of the proposed systems to handle a broader class of malicious behaviors. Also, we are interested in improving the efficiency of the homomorphic cipher, particularly in the case when small plaintext numbers are used. Another topic under investigation is the scalability of the
-Anonymous Quantization has been devised to derive the optimal quantization that maximizes privacy. Secure procedures have been proposed to perform the dimensional reduction and cell lookup. Experimental results on a dataset of iris patterns demonstrate the effectiveness of our techniques in terms of balancing privacy and computational costs. We are currently investigating the extension of the proposed systems to handle a broader class of malicious behaviors. Also, we are interested in improving the efficiency of the homomorphic cipher, particularly in the case when small plaintext numbers are used. Another topic under investigation is the scalability of the  -Anonymous Quantization to a much larger dataset.
-Anonymous Quantization to a much larger dataset.
References
Associated Press,Jesdanun A: Youtube, Vacom Agree to Mask Viewer Data. Associated Press; 2007.
IOS Press,Hassan W, Logrippo L: Governance policies for privacy access control and their interactions. In Feature Interactions in Telecommunication and Software Systems VIII. Edited by: Amyot D, Logrippo L. IOS Press; 2005:114-130.
Sweeney L:
 -anonymity: a model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 2002, 10(5):557-570. 10.1142/S0218488502001648
-anonymity: a model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 2002, 10(5):557-570. 10.1142/S0218488502001648Ratha NK, Connell JH, Bolle RM: Enhancing security and privacy in biometrics-based authentication systems. IBM Systems Journal 2001, 40(3):614-634.
Hoque S, Fairhurst M, Howells G, Deravi F: Feasibility of generating biometric encryption keys. Electronics Letters 2005, 41(6):309-311. 10.1049/el:20057524
Uludag U, Jain A: Securing fingerprint template: fuzzy vault with helper data. Proceedings of the Computer Vision and Pattern Recognition Workshops (CVPR '06), June 2006 163.
Newton EM, Sweeney L, Malin B: Preserving privacy by de-identifying face images. IEEE Transactions on Knowledge and Data Engineering 2005, 17(2):232-243.
Ciriani V, di Vimercati SDC, Foresti S, Samarati P:
 -anonymity. In Secure Data Management in Decentralized Systems. Volume 33. Springer, New York, NY, USA; 2007:323-353. 10.1007/978-0-387-27696-0_10
-anonymity. In Secure Data Management in Decentralized Systems. Volume 33. Springer, New York, NY, USA; 2007:323-353. 10.1007/978-0-387-27696-0_10Goldreich O: Foundations of Cryptography: Volume II Basic Applications. Cambridge University Press, Cambridge, UK; 2004.
Goethals B, Laur S, Lipmaa H, Mielikäinen T: On private scalar product computation for privacy-preserving data mining. Proceedings of the 7th Annual International Conference in Information Security and Cryptology (ICISC '04), December 2005, Seoul, South Korea 3506: 104-120.
Naor M, Pinkas B: Oblivious polynomial evaluation. SIAM Journal on Computing 2006, 35(5):1254-1281. 10.1137/S0097539704383633
Chang Y-C, Lu C-J: Oblivious polynomial evaluation and oblivious neural learning. Theoretical Computer Science 2005, 341(1–3):39-54.
Naor M, Pinkas B: Oblivious transfer and polynomial evaluation. Proceedings of the 31st Annual ACM Symposium on Theory of Computing (STOC '99), May 1999, Atlanta, Ga, USA 245-254.
Damgard I, Geisler M, Kroigard M: Homomorphic encryption and secure comparison. International Journal of Applied Cryptography 2008, 1(1):22-31. 10.1504/IJACT.2008.017048
Fischlin M: A cost-effective pay-per-multiplication comparison method for millionaires. Proceedings of the Conference on Topics in Cryptology: The Cryptographer's Track at RSA (CT-RSA '2001), April 2001, San Francisco, Calif, USA, Lecture Notes in Computer Science 2020: 457-472.
Yao AC: Protocols for secure computations. Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (FOCS '82), 1982 160-164.
Aggarwal G, Mishra N, Pinkas B:Secure computation of the
 -ranked element. Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT '04), 2004, Lecture Notes in Computer Science 3027: 40-55.
-ranked element. Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT '04), 2004, Lecture Notes in Computer Science 3027: 40-55.Kiltz E, Mohassel P, Weinreb E, Franklin M: Secure linear algebra using linearly recurrent sequences. Proceedings of the 4th Theory of Cryptography Conference (TCC '07), February 2007, Amsterdam, The Netherlands, Lecture Notes in Computer Science 4392: 291-310.
Cramer R, Damgaard I: Secure distributed linear algebra in constant number of rounds. In Proceedings of the 21st Annual International Cryptology Conference on Advances in Cryptology (IACR CRYPTO '01), 2001, Lecture Notes In Computer Science. Volume 2139. Springer; 119-136.
Schoenmakers B, Tuyls P: Efficient binary conversion for Paillier encrypted values. Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT '06), May-June 2006, St. Petersburg, Russia, Lecture Notes in Computer Science 4004: 522-537.
Jagannathan G, Pillaipakkamnatt K, Wright RN:A new privacy-preserving distributed
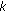 -clustering algorithm. Proceedings of the 6th SIAM International Conference on Data Mining (SDM '06), 2006 494-498.
-clustering algorithm. Proceedings of the 6th SIAM International Conference on Data Mining (SDM '06), 2006 494-498.Doganay MC, Pedersen TB, Saygin Y, Savaş E, Levi A:Distributed privacy preserving
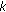 -means clustering with additive secret sharing. Proceedings of the International Workshop on Privacy and Anonymity in Information Society (PAIS '08), 2008, Nantes, France 331: 3-11.
-means clustering with additive secret sharing. Proceedings of the International Workshop on Privacy and Anonymity in Information Society (PAIS '08), 2008, Nantes, France 331: 3-11.Samet S, Miri A: Privacy preserving ID3 using gini index over horizontally partitioned data. Proceedings of the 6th IEEE/ACS International Conference on Computer Systems and Applications (AICCSA '08), March-April 2008 645-651.
Zhan J: Privacy-preserving decision tree classification in horizontal collaboration. Proceedings of the 1st International Conference on Security of Information and Networks (Sin '07), 2007
Lindell Y, Pinkas B: Privacy preserving data mining. Journal of Cryptology 2002, 15(3):177-206. 10.1007/s00145-001-0019-2
Vaidya J, Yu H, Jiang X: Privacy-preserving SVM classification. Knowledge and Information Systems 2008, 14(2):161-178. 10.1007/s10115-007-0073-7
Orlandi C, Piva A, Barni M: Oblivious neural network computing via homomorphic encryption. EURASIP Journal on Information Security 2007, 2007:-11.
Wright R, Yang Z: Privacy-preserving Bayesian network structure computation on distributed heterogeneous data. Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '04), 2004, Seattle, Wash, USA 713-718.
Cheung S-C, Nguyen T: Secure signal processing between distrusted network terminals. EURASIP Journal on Information Security 2007, 2007:-10.
Harvar Aiken Computation Laboratory,Rabin MO: How to exchange secrets by oblivious transfer. TR-81 Harvar Aiken Computation Laboratory; 1981.
Boneh D, Goh E-J, Nissim K: Evaluating 2-DNF formulas on ciphertexts. In Proceedings of the Theory of Cryptography Conference (TCC '05), 2005, Lecture Notes in Computer Science. Volume 3378. Edited by: Killian J. Springer, New York, NY, USA; 325-342.
Naor M, Pinkas B: Efficient oblivious transfer protocols. Proceedings of the Annual ACM-SIAM Symposium on Discrete Algorithms (SODA '01), January 2001, Washington, DC, USA 448-457.
Naor M, Nissim K: Communication complexity and secure function evaluation. Proceedings of the Electronic Colloquium on Computational Complexity (ECCC '01), 2001 8:
Cachin C, Camenisch J, Kilian J, Muller J: One-round secure computation and secure autonomous mobile agents. Proceedings of the 27th International Colloquium on Automata, Languages and Programming (ICALP '00), July 2000, Geneva, Switzerland 512-523.
Fontaine C, Galand F: A survey of homomorphic encryption for nonspecialists. EURASIP Journal on Information Security 2007, 2007:-10.
Gentry C: Fully homomorphic encryption using ideal lattices. Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC '09), 2009, Bethesda, Md, USA 169-179.
Cooney M: Ibm touts encryption innovation. Computer World, June 2009
Schneier B: Homomoprhic encryption breakthrough. Schneier on Security 2009.
Pailler P: Public-key cryptosystems based on composite degree residuosity classes. Proceedings of the International Conference on the Theory and Application of Cryptographic Techniques (EUROCRYPT '99), May 1999 1592: 223-238.
Erkin Z, Piva A, Katzenbeisser S, et al.: Protection and retrieval of encrypted multimedia content: when cryptography meets signal processing. EURASIP Journal on Information Security 2007, 2007:-20.
Bianchi T, Piva A, Barni M: Discrete cosine transform of encrypted images. Proceedings of the 15th IEEE International Conference on Image Processing (ICIP '08), October 2008 1668-1671.
Daugman J: How iris recognition works. IEEE Transactions on Circuits and Systems for Video Technology 2004, 14(1):21-30. 10.1109/TCSVT.2003.818350
Hotelling H: Analysis of a complex of statistical variables into principal components. Journal of Educational Psychology 1933, 24(6):417-441.
Cox TF, Cox MA: Multidimensional Scaling. 2nd edition. Chapman & Hall, Boca Raton, Fla, USA; 2001.
Faloutsos C, Lin K-I: Fastmap: a fast algorithm for indexing, data-mining and visualization of traditional and multimedia datasets. Proceedings of the ACM International Conference on Management of Data (SIGMOD '95), May 1995, San Jose, Calif, USA 163-174.
Bourgain J: On lipschitz embedding of finite metric spaces in Hilbert space. Israel Journal of Mathematics 1985, 52(1-2):46-52. 10.1007/BF02776078
Gionis A, Indyk P, Motwani R: Similarity search in high dimneions via hashing. Proceedings of the 25th International Conference on Very Large Data Bases (VLDB '99), September 1999 518-529.
Goldreich O: Foundations of Cryptography: Volume 1, Basic Tools. Cambridge University Press, Cambridge, UK; 2007.
Mohanty P, Sarkar S, Kasturi R: Privacy & security issues related to match scores. Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW '06), June 2006 162-165.
Katz J, Lindell Y: Introduction To Modern Cryptography. Chapman & Hall, Boca Raton, Fla, USA; 2008.
Masek L, Kovesi P: Matlab source code for a biometric identification system based on iris patterns. The School of Computer Science and Software Engineering, The University of Western Australia, Perth, Australia; 2003.
Filho D, Barreto P: Demonstrating data possession and uncheatable data transfer. Cryptology ePrint Archive, Report 2206/150, 2006
Krohn MN, Freedman MJ, Mazières D: On-the-fly verification of rateless erasure codes for efficient content distribution. Proceedings of the IEEE Symposium on Security and Privacy (S&P '04), May 2004, Berkeley, Calif, USA 2004: 226-240.
Tan T, Sun Z: Casia-irisv3. Chinese Academy of Sciences Institute of Automation; 2005.http://www.cbsr.ia.ac.cn/IrisDatabase.htmhttp://www.cbsr.ia.ac.cn/IrisDatabase.htm
Bethencourt JPaillier Library, UC Berkeley, http://acsc.cs.utexas.edu/
 -anonymity: a model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 2002, 10(5):557-570. 10.1142/S0218488502001648
-anonymity: a model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 2002, 10(5):557-570. 10.1142/S0218488502001648 -anonymity. In Secure Data Management in Decentralized Systems. Volume 33. Springer, New York, NY, USA; 2007:323-353. 10.1007/978-0-387-27696-0_10
-anonymity. In Secure Data Management in Decentralized Systems. Volume 33. Springer, New York, NY, USA; 2007:323-353. 10.1007/978-0-387-27696-0_10 -ranked element. Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT '04), 2004, Lecture Notes in Computer Science 3027: 40-55.
-ranked element. Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT '04), 2004, Lecture Notes in Computer Science 3027: 40-55.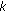 -clustering algorithm. Proceedings of the 6th SIAM International Conference on Data Mining (SDM '06), 2006 494-498.
-clustering algorithm. Proceedings of the 6th SIAM International Conference on Data Mining (SDM '06), 2006 494-498.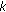 -means clustering with additive secret sharing. Proceedings of the International Workshop on Privacy and Anonymity in Information Society (PAIS '08), 2008, Nantes, France 331: 3-11.
-means clustering with additive secret sharing. Proceedings of the International Workshop on Privacy and Anonymity in Information Society (PAIS '08), 2008, Nantes, France 331: 3-11.Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Ye, S., Luo, Y., Zhao, J. et al. Anonymous Biometric Access Control. EURASIP J. on Info. Security 2009, 865259 (2009). https://doi.org/10.1155/2009/865259
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2009/865259