- Research Article
- Open access
- Published:
Novel Attacks on Spread-Spectrum Fingerprinting
EURASIP Journal on Information Security volume 2008, Article number: 803217 (2008)
Abstract
Spread-spectrum watermarking is generally considered to be robust against collusion attacks, and thereby suitable for digital fingerprinting. We have previously introduced the minority extreme attack (IWDW' 07), and showed that it is effective against orthogonal fingerprints. In this paper, we show that it is also effective against random Gaussian fingerprint. Furthermore, we develop new randomised attacks which counter the effect of the decoder preprocessing of Zhao et al.
1. INTRODUCTION
Unauthorised copying is a major worry for many copyright holders. As digital equipment enables perfect copies to be created on amateur equipment, many are worried about lost revenues, and steps are introduced to reduce the problem. Technology to prevent copying has been along for a long time, but it is often controversial because it not only prevents unauthorised copying, but also a lot of the legal and fair use.
A different approach to the problem is to deter potential offenders using technology to allow identification after the crime. Thus, the crime is not prevented, but the guilty users can be prosecuted. If penalties are sufficiently high, potential pirates are unlikely to accept the risk of being caught.
One such solution is digital fingerprinting, first proposed by Wagner [1]. Each copy of the copyrighted file is marked by hiding a fingerprint identifying the buyer. Illegal copies can then be traced back to one of the legitimate copies and the guilty user be identified. Obviously, the marking must be made such that the user cannot remove the fingerprint without ruining the file. Techniques to hide data in a file in such a way are known as robust watermarking. All references to watermarking (WM) in this paper refer to robust watermarking.
A group of users can compare their individual copies and observe differences caused by the different fingerprints embedded. By exploiting this information they can mount so-called collusive attacks. There is a growing literature on collusion-secure fingerprinting, both from mathematical and abstract and from practical view-points.
In this paper, we focus on Gaussian, spread-spectrum fingerprinting, where each user is identified by a random, Gaussian signal which is added to the copyrighted file (host signal). Our main purpose is to demonstrate that there are collusion attacks which are more effective than the ones studied by Zhao et al. [2]. We make extensive experiments to compare the various attacks. Our starting point is the minority extreme attack introduced in [3] in a context of non-Gaussian fingerprints.
The outline of the paper is as follows. We will introduce our model for fingerprinting in general and spread spectrum fingerprinting in particular in Section 2. We introduce our new collusion attacks in Section 3, and consider noise attacks in Section 4. In Section 5, we make a further evaluation, testing the attacks under different conditions. Finally, there is a conclusion in Section 6.
2. FINGERPRINTING MODELS
There are several different approaches to fingerprinting. It is often viewed as a layered system. In the fingerprinting (FP) layer, each user is identified by a codeword  , that is, an
, that is, an  -tuple of symbols from a discrete
-tuple of symbols from a discrete  -ary alphabet. If there are
-ary alphabet. If there are  codewords (users), we say that they form an
codewords (users), we say that they form an  code.
code.
In the watermarking (WM) layer, the copyrighted file is divided into  segments. When a codeword
segments. When a codeword  is embedded, each symbol of
is embedded, each symbol of  is embedded independently in one segment.
is embedded independently in one segment.
The layered model allows independent solutions for each layer. Coding for the FP layer is known as collusion-secure codes and was introduced in [4]. A number of competing abstract models have been suggested, and mathematically secure solutions exist for most of the models.
In principle, any robust watermarking scheme can be used in the WM layer. However, there has been little research into WM systems which supports the abstract models assumed for the collusion-secure codes, thus it is not known whether existing collusion-secure is applicable to a practical system. Recent studies of this interface are found in [5, 6], but they rely on experimental studies with few selected attacks, and the mathematical model has not been validated.
In this paper, we will consider a simpler class of solutions, exploiting some inherent collusion resistance in spread-spectrum watermarking. We focus on the solution suggested in [2].
2.1. Spread-spectrum fingerprinting
We view the copyrighted file as a signal  , called the host signal, of real or floating-point values
, called the host signal, of real or floating-point values  . Each user
. Each user  is identified by a watermark signal
is identified by a watermark signal over the same domain as the host signal. The encoder simply adds the two signals to produce a watermarked copy
over the same domain as the host signal. The encoder simply adds the two signals to produce a watermarked copy for distribution.
for distribution.
A goal is to design the watermark  so that
so that  and
and  are perceptually as similar as possible. No perfect measure is known to evaluate perceptual similarity. He and Wu [5] use the peak signal-to-noise ration (PSNR). Zhao et al. [2] consider the just noticeable difference (JND) as the smallest, perceptible change which can be made to a single sample, and they measure distortion as the mean square error (MSE) ignoring samples with distortion less than some threshold (called JND). This heuristic is called
are perceptually as similar as possible. No perfect measure is known to evaluate perceptual similarity. He and Wu [5] use the peak signal-to-noise ration (PSNR). Zhao et al. [2] consider the just noticeable difference (JND) as the smallest, perceptible change which can be made to a single sample, and they measure distortion as the mean square error (MSE) ignoring samples with distortion less than some threshold (called JND). This heuristic is called  .
.
In the system of [2], which we study, the watermark signals  are drawn independently at random from a normal distribution with variance
are drawn independently at random from a normal distribution with variance  and mean
and mean  .
.
It is commonly argued that in most fingerprinting applications, the original file will be known by the decoder, so that nonblind detection can be used [2, 5]. Let  denote the received signal, such as an intercepted unauthorised copy. Knowing
denote the received signal, such as an intercepted unauthorised copy. Knowing  , the receiver can compute the received watermark
, the receiver can compute the received watermark , which is the input to the decoder.
, which is the input to the decoder.
The adversary, the copyright pirates in the case of fingerprinting, will try to disable the watermark by creating an attacked copy  which is perceptually equivalent to
which is perceptually equivalent to  , but where the watermark cannot be correctly interpreted. In the case of a collusion attack, there is a group of pirates each possessing one watermarked copy
, but where the watermark cannot be correctly interpreted. In the case of a collusion attack, there is a group of pirates each possessing one watermarked copy  .
.
An overview of the symbols introduced can be seen in Table 1.
2.2. Fingerprint decoding
For any signal  , let
, let  denote its average, that is
denote its average, that is

The Euclidean norm is denoted by

The correlation of two signals is denoted by

The simplest decoding algorithm would return the user solving  . This is sometimes used, but more often some kind of normalisation is recommended.
. This is sometimes used, but more often some kind of normalisation is recommended.
2.2.1. The general decoder
Following [2], we study three heuristics which assign a numerical value  to any pair of signals
to any pair of signals  and
and  . Each heuristic
. Each heuristic  can be used either for list decoding or for maximum heuristic decoding. The latter returns the user
can be used either for list decoding or for maximum heuristic decoding. The latter returns the user  solving
solving  . A list decoder would return all users
. A list decoder would return all users  such that
such that  for some threshold
for some threshold  .
.
The performance measure for a maximum heuristic decoder is simply the error rate. Only one user is output, who is either guilty (correct) or not (error). List decoder performance cannot be described by a single parameter. The output may be empty (false negative); it may include innocent users (false positive); or it may be a nonempty set of guilty users only (correct decoding). The trade-off between false positive and false negative error rates is controlled by the threshold  .
.
One may also want to consider the number of guilty users returned by the list decoder. If two decoders have identical error rates, one would clearly prefer one which tends to return two guilty users instead of just one.
It should be noted that a list decoder can never have a higher probability of correct decoding than a maximum heuristic decoder for the same heuristic. When the list decoder decodes correctly, the user with the maximum heuristic will clearly be in the output set and also be correctly returned by the maximum heuristic decoder.
We will mainly consider the maximum heuristic decoder. This does provide a bound on the performance of a list decoder, and we avoid any potential controversies in the choice of  .
.
2.2.2. Decoding heuristics
The so-called  statistic is simply normalised correlation, defined as follows:
statistic is simply normalised correlation, defined as follows:

From the attacker's point of view, this is the easiest heuristic to analyse, as it is linear in each sample of  .
.
The most effective heuristic according to the experiments of [2] is the so-called  statistic, defined as
statistic, defined as

where

where  is the mean of
is the mean of  and
and  is the empirical standard deviation, that is,
is the empirical standard deviation, that is,

The final statistic is the  statistic, which is based on the mean
statistic, which is based on the mean  and standard deviation
and standard deviation  of the signal
of the signal  . It is defined as
. It is defined as

Observe that  . Thus, all the three heuristics are based on correlation.
. Thus, all the three heuristics are based on correlation.
2.2.3. Preprocessing
Zhao et al. [2] point out that the three decoding heuristics presented have not been designed for collusion-resistance in particular. In order to improve the performance, they introduce a preprocessing step. The theoretical foundation is not very clear in their paper, but it works well experimentally. Our simulations have confirmed this.
They considered the histogram of the received watermark  at the decoder for various attacks presented in Section 2.3.
at the decoder for various attacks presented in Section 2.3.
The median, average, and midpoint attacks roughly produce normal distribution with zero mean. The Min and Max attacks give normal distributions with nonzero means (negative and positive means, resp.). The RandNeg attacks give a histogram with two peaks, one positive and one negative. Very few samples are close to zero.
In the case of the single peak, the preprocessor subtracts the mean, to return  . In the case of a double peak, the samples are divided into two subsets, one for negative values and one for positive ones. The mean is calculated and subtracted independently for each subset.
. In the case of a double peak, the samples are divided into two subsets, one for negative values and one for positive ones. The mean is calculated and subtracted independently for each subset.
Zhao et al. gave no definition of a peak in the histogram, and no algorithm to identify them automatically. As long as we are restricted to the known attacks, this is only a minor problem. It is obvious from visual inspection which case we are in.
We will, however, introduce attacks where it is not clear which preprocessor mode to use. In these cases we will test both modes, so Preproc(1) denotes the preprocessor assuming two peaks, and Preproc(2) is the preprocessor assuming a single peak.
2.3. Spread spectrum collusion attacks
The collusion attack is mounted by a collusion of pirates, each of whom has a watermarked copy  perceptually equivalent to the (unknown) host
perceptually equivalent to the (unknown) host  . The most commonly studied attacks are functions working independently on each sample
. The most commonly studied attacks are functions working independently on each sample  , that is,
, that is,  , where
, where  is the set of colluder watermarks.
is the set of colluder watermarks.
Both randomised and deterministic attack functions  have been studied. In principle,
have been studied. In principle,  could depend on the entire signal, and not only on the samples corresponding to the output sample, but this possibility has received little attention in the literature. Our starting point is the following range of attacks which were analysed in [2].
could depend on the entire signal, and not only on the samples corresponding to the output sample, but this possibility has received little attention in the literature. Our starting point is the following range of attacks which were analysed in [2].

It was assumed in [2], that  for the randomised negative attack be independent of the signals
for the randomised negative attack be independent of the signals  .
.
The analysis of [2] demonstrated that the randomised negative attack gave the highest error rate against decoders without preprocessing. None of the attacks were effective against decoders with preprocessing for the parameters studied. The average attack gives the lowest distortion of all the attacks. This is obvious as it is known as a good estimate for the original host  .
.
2.4. Collusion attacks and collusion-secure codes
It is instructive to consider attacks commonly considered in the literature on collusion-secure codes. Recall that the fingerprint  in the context of collusion-secure codes is not a numerical signal, but rather a word (vector) over a discrete alphabet
in the context of collusion-secure codes is not a numerical signal, but rather a word (vector) over a discrete alphabet  . The basic operations of average, minimum, and maximum are not defined on this alphabet.
. The basic operations of average, minimum, and maximum are not defined on this alphabet.
The so-called marking assumption defines which attacks are possible in the model. In the original scenario of [4], the pirates can produce an output symbol  , if and only if
, if and only if  . In a more realistic scenario [6, 7], the pirates can produce a symbol
. In a more realistic scenario [6, 7], the pirates can produce a symbol  with probability
with probability  . However, with probability
. However, with probability  , we have
, we have  .
.
It is generally known that the so-called minority choice attack is very effective if correlation decoding (or, equivalently, closest neighbour decoding) is used. In this attack the output is the symbol  minimising the number of colluders
minimising the number of colluders  with
with  .
.
The rationale for this attack is straight forward. All the colluders  with
with  gets a positive contribution to the correlation from sample
gets a positive contribution to the correlation from sample  ; all the other users get a negative contribution. Hence, the minority choice minimises the average correlation of the colluders.
; all the other users get a negative contribution. Hence, the minority choice minimises the average correlation of the colluders.
The minority choice attack does not apply directly to Gaussian fingerprints. With each watermark drawn randomly from a continuous set, one would expect all the samples  seen by the pirates to be distinct. However, we will see that we can construct an effective attack based on the same idea.
seen by the pirates to be distinct. However, we will see that we can construct an effective attack based on the same idea.
2.5. Evaluation methodology
There are two important characteristics for the evaluation of fingerprinting attacks.
Success rate: The attack succeeds when an error occurs at the watermark decoder.
Distortion: The unauthorised copy has to pass in place of the original, so it should be as close as possible to the unknown signal  perceptually.
perceptually.
The success rate of the attack is the resulting error rate at the decoder/detector. As long as we use a maximum heuristic decoder, this is a single figure. In the event of list decoding, it is more complex as explained in Section 2.2.1.
Distortion is, following [2], measured by the  as defined below.
as defined below.
Definition 1 (just notable difference).
Given a signal  , the just noticeable difference,
, the just noticeable difference,  , is the smallest positive real number, such that
, is the smallest positive real number, such that  is perceptually different from
is perceptually different from  .
.
In our simulations we have assumed, without loss of generality, that  for all
for all  . The general case is achieved by scaling each sample of the fingerprint signal by factor of
. The general case is achieved by scaling each sample of the fingerprint signal by factor of  before embedding, and rescale before decoding.
before embedding, and rescale before decoding.
Definition 2.
The  between to signal
between to signal  and
and  is defined as
is defined as

It is natural to expect low distortion from the average, median, and midpoint attacks. The pirate collusion is likely to include both positive and negative fingerprint signals. Consequently, these attacks are likely to produce a hybrid which is closer to the original sample than any of the colluder fingerprints. On the contrary, the maximum, minimum, and randomised negative attacks would tend to give a very distorted hybrid, by using the most distorted version of each sample. This is experimentally confirmed in [2, 8].
Not surprisingly, the most effective attacks are the most distorting. The most effective attack according to [8] is the randomised negative, but the authors raise some doubt that it be practical due to the distortion.
The performance of existing fingerprinting schemes and joint WM/FP schemes have been analysed experimentally or theoretically. Very few systems have been studied both experimentally and theoretically. In the cases where both theoretical and experimental analyses exist, there is a huge discrepancy between the two.
It is not surprising that theoretical analyses are more pessimistic than experimental ones. An experimental simulation (e.g., [5]) has to assume one (or a few) specific attack(s). An adversary who is smarter (or more patient) than the author and analyst may very well find an attack which is more effective than any attack analysed. Thus, the experimental analyses give lower bounds on the error rate of the decoder, by identifying an attack which achieves the bound.
The theoretical analyses of the collusion-secure codes of [4, 9, 10] give mathematical upper bounds on the error rate under any attack provided that the appropriate marking assumption holds. Of course, attacks on the WM layer (which is not considered by those authors) may very well break the assumptions and thereby the system. Unfortunately, little work has been done on theoretical upper bounds for practical fingerprints embedded in real data.
In any security application, including WM/FP schemes, the designer has a much harder task than the attacker. The attacker only needs to find one attack which is good enough to break the system, and this can be confirmed experimentally. The designer has to find a system which can resist every attack, and this is likely to require a complex argument to be assuring.
This paper will improve the lower bounds (experimental bounds) for Gaussian spread spectrum fingerprinting, by identifying more complex nonlinear attacks, which are more effective than those originally studied. These attacks are likely to be effective against other joint schemes as well.
3. THE NOVEL ATTACKS
In this section, we will consider four new classes of attacks. The minority extreme attack was introduced in a different model in [3], and the uniform attack is introduced in this paper. The last two classes of attacks are hybrid attacks, behaving as different pure attacks either at random or depending on the collusion signals. We introduce each attack separately with its rationale and simulation results. In the next section we will consider noise attacks.
Let  be the watermark identifying user
be the watermark identifying user  , and let
, and let  be the hybrid watermark generated by the collusion. All the heuristics we consider include the correlation
be the hybrid watermark generated by the collusion. All the heuristics we consider include the correlation

In order to avoid detection, the pirates should attempt to minimise  . Without complete knowledge of the original host
. Without complete knowledge of the original host  and the watermark signals used, an accurate minimisation is intractable. However, attempting to minimise
and the watermark signals used, an accurate minimisation is intractable. However, attempting to minimise  is a reasonable approximation, and this can be done by minimising sample by sample,
is a reasonable approximation, and this can be done by minimising sample by sample,  .
.
All the simulations in this section use sequences of length  with
with  users. The sequences are drawn from a normal distribution of mean
users. The sequences are drawn from a normal distribution of mean  and variance
and variance  .
.
With the exception of the code size (i.e., the number of users), these are the same parameters as used in [2]. There are two reasons for using larger codes. Firstly, it is hard to come up with plausible applications for small codes. Secondly, and more importantly, larger codes give higher error rates which can be estimated more accurately.
For each simulation,  different codes are created, and one hybrid fingerprint is generated and decoded for each code. Although this is a smaller sample size than the 2000 tests used in [2], it is appropriate for tuning the attack parameters. In the next section we will run larger simulations for a more significant comparison to previous work.
different codes are created, and one hybrid fingerprint is generated and decoded for each code. Although this is a smaller sample size than the 2000 tests used in [2], it is appropriate for tuning the attack parameters. In the next section we will run larger simulations for a more significant comparison to previous work.
3.1. The minority extreme attack
We introduced the moderated minority extreme (MMX) attack in [3] in order to break the joint scheme of [5]. Consider the difference  . Since
. Since  is an unbiased estimate for the unknown host
is an unbiased estimate for the unknown host  , a positive
, a positive  indicates that
indicates that  is probably positive. In this case, the minimum attack is good for the pirates.
is probably positive. In this case, the minimum attack is good for the pirates.
If  , we expect that the choice for
, we expect that the choice for  makes little difference to the decoding. In this case, we output
makes little difference to the decoding. In this case, we output  to minimise the distortion in the hybrid copy.
to minimise the distortion in the hybrid copy.
Definition 3 (moderated minority extreme attack).
Let  . The MMX attack for a given threshold
. The MMX attack for a given threshold  outputs the hybrid signal
outputs the hybrid signal  , where
, where

The MMX attack with  was called the minority extreme (MX) attack [3]. Figure 1 shows a simulation of the MX and RandNeg attack. We observe that the MX attack causes a slightly higher error rate, confirming that the criterion that
was called the minority extreme (MX) attack [3]. Figure 1 shows a simulation of the MX and RandNeg attack. We observe that the MX attack causes a slightly higher error rate, confirming that the criterion that  is better than a random choice. However, with preprocessing, the error rate is zero for both attacks. The average attack was tested as well, but it gave zero errors with all of the tested decoders. These results are consistent with those reported in [2].
is better than a random choice. However, with preprocessing, the error rate is zero for both attacks. The average attack was tested as well, but it gave zero errors with all of the tested decoders. These results are consistent with those reported in [2].

Comparing MX against RandNeg. Decoding with preprocessing gives zero errors throughout.
Figure 2 shows, unfortunately, that the MX attack also causes about twice the distortion of RandNeg. Given the very modest increase in error rate, the MX attack is unlikely to be useful in itself.

Distortion of pure attacks.
3.2. The uniform attack
So far we have seen that the preprocessor of Zhao et al. is very effective against the attacks considered to date. Somehow we need to break the preprocessing scheme.
Remember that the preprocessor considers the histogram and split the samples into two classes around each histogram peak. An attack which produces a near-flat histogram seems the natural choice. Our proposal is to draw each hybrid sample a uniformly at random between the minimum and maximum observed. This is defined formally as follows.
Definition 4 (the uniform attack).
The uniform attack ("uniatk") takes  watermarked signals
watermarked signals  , and produces a hybrid copy
, and produces a hybrid copy  where each sample
where each sample  is drawn independently and uniformly at random on the interval
is drawn independently and uniformly at random on the interval  .
.
Figure 3 shows example histograms of the MX and uniform attacks. We can clearly see how the MX attack gives a histogram resembling that of the RandNeg attack, while the uniform attack achieves the flatness sought.

Histogram of a hybrid copies. MX attackUniform attack
Figure 4 shows simulations of the uniform attack compared to the MX attack. The important feature to note is that the behaviour is very similar for all the decoding options. The error rate is lower than for the MX decoder without preprocessor, but for the uniform attack the preprocessor does not help. Furthermore, as seen in Figure 2, the uniform attack causes very little distortion. For large collusions it seems to have an excellent potential.

Comparing the uniform attack against MMX and the classics.
3.3. Hybrid attacks
The uniform attack is the bluntest way to produce a flat histogram, and as we see, it breaks the preprocessing. An interesting question is if better attacks can be developed by combining the basic attacks already introduced. We introduce hybrid attacks as the attack is chosen independently for each sample according to some probability distribution.
In Figure 5, we have compared hybrid attacks which use the uniform attack with probability  , and, respectively, the MMX or the RandNeg attacks with probability
, and, respectively, the MMX or the RandNeg attacks with probability  . As expected there is a significant difference between one-peak and two-peak preprocessing, but the most interesting feature is that different decoding strategies are optimal for different
. As expected there is a significant difference between one-peak and two-peak preprocessing, but the most interesting feature is that different decoding strategies are optimal for different  . The curves cross around
. The curves cross around  . Typical histograms at for
. Typical histograms at for  are shown in Figure 6.
are shown in Figure 6.

Comparing hybrid attacks for  colluders. Error rate—RandNeg/uniformDistortion—RandNeg/uniformError rate—MX/uniformDistortion—MX/uniform
colluders. Error rate—RandNeg/uniformDistortion—RandNeg/uniformError rate—MX/uniformDistortion—MX/uniform

Histogram of hybrid copies from hybrid attacks with  . Uniform/RandNegUniform/MX
. Uniform/RandNegUniform/MX
At the expense of increased distortion, these hybrid attacks allows us to increase the error rates compared to the pure uniform attack. This is true up to the point, where the histogram gets a distinctive two-peak shape and Preproc(1) becomes effective.
3.4. Hybrid attacks with MMX threshold
An alternative to the randomised hybrid attacks just described is to base the choice on a threshold. This is already part of the idea in the MMX attack. If the heuristic  is close to zero, an average attack is used, and otherwise the MX attack (minimum or maximum) is used. Obviously, other combinations are also possible, and we also introduce the MMX-2 attack, where the average is replaced by the uniform attack.
is close to zero, an average attack is used, and otherwise the MX attack (minimum or maximum) is used. Obviously, other combinations are also possible, and we also introduce the MMX-2 attack, where the average is replaced by the uniform attack.
In Figure 7, we have simulated the MMX with different thresholds. The result is similar to what we saw for the previous hybrid attacks, but even more pronounced. The single-peak preprocessor has no significant effect and has been excluded from the figure. The two-peak preprocessor is effective for small thresholds. The curves cross around  .
.

The MMX attack with different thresholds. Error rate (35 pirates)Distortion (35 pirates)Error rate (70 pirates)Distortion (70 pirates)
Typical histograms are shown in Figure 8 at  . For the MMX-2 attack, we have the same flattish histogram as before, and no obvious approach preprocessing can be seen. However, for the regular MMX(-1) attack, we see a new pattern, with three peaks. It seems plausible that a preprocessor can be developed to decode correctly in this scenario, but, unless manual interference is acceptable, a strict definition of a peak would have to be developed.
. For the MMX-2 attack, we have the same flattish histogram as before, and no obvious approach preprocessing can be seen. However, for the regular MMX(-1) attack, we see a new pattern, with three peaks. It seems plausible that a preprocessor can be developed to decode correctly in this scenario, but, unless manual interference is acceptable, a strict definition of a peak would have to be developed.

Histogram of a hybrid copies with MMX attacks at threshold  . MMX-1MMX-2
. MMX-1MMX-2
4. THE NOISE ATTACK
He and Wu [5], citing [2], claim that "a number of nonlinear collusions can be well approximated by an averaging collusion plus additive noise." We did not find any explicit details on this claim in either paper, neither on the recommended noise distribution, nor on which nonlinear attacks can be so approximated. However, it is an interesting claim to explore.
We consider the following two attacks:

where  is drawn from a standard normal distribution, and
is drawn from a standard normal distribution, and  is uniformly distributed on
is uniformly distributed on  . The first simulation, for
. The first simulation, for  pirates, is shown in Figure 9. As we can see, both attacks are effective, but Gaussian noise causes enormous distortion.
pirates, is shown in Figure 9. As we can see, both attacks are effective, but Gaussian noise causes enormous distortion.

The averaging with noise attack by 70 pirates with different thresholds. Error rateDistortion
To get a better picture, we plot the noise attacks against distortion in Figures 10 and 11. We have shown decoding of the noise attacks without preprocessor only; decoding with preprocessing is less effective. Supported by Figure 7, we decode the MMX attack without preprocessor only and MMX-2 without and with Preproc(1).

Noise versus the MMX attacks. 35 pirates70 pirates

Noise versus hybrid attacks. 35 pirates70 pirates
Three observations stand out as significant in this comparison:
-
(i)
attacks with uniform noise are very effective for given distortion compared to other attacks,
-
(ii)
attacks with Gaussian noise are considerably less effective than Uniform noise, and inferior to several other attacks studied,
-
(iii)
for few pirates (
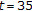 ) the distortion/error rate trade-off is much steeper for MMX-1 than for the noise attack, and it outperforms it at high distortion (150–200).
) the distortion/error rate trade-off is much steeper for MMX-1 than for the noise attack, and it outperforms it at high distortion (150–200).
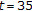 ) the distortion/error rate trade-off is much steeper for MMX-1 than for the noise attack, and it outperforms it at high distortion (150–200).
) the distortion/error rate trade-off is much steeper for MMX-1 than for the noise attack, and it outperforms it at high distortion (150–200).Now, if a three-peak Zhao et al. type preprocessor is used, the MMX-1 attack is likely to become ineffective.
We conclude that there may be some truth in the claims that averaging attacks with added noise are the most efficient attacks known to date. However, two important points have to be noted in this context. Firstly, the noise should not be Gaussian. We do not know if Uniform noise is optimal, or if an even better distribution can be found. Secondly, the preprocessor of Zhao et al. has to be developed further to be able to cope, automatically, with all the various attacks we have studied.
5. EVALUATION
In this section, we report additional simulations of the attacks which have proved most effective so far, to see how they compare under different conditions, that is, varying  ,
,  , and
, and  .
.
We have not include simulations with real images, because all the processes studied are oblivious to any added host signal. The detector is nonblind so any host added would be subtracted before detection. Also the attacks would be unaffected by the added host signal. Hence, simulations with real hosts would not give us any additional information.
The constants, namely, the power of the fingerprint and the value of the Just Noticeable Difference would be scaled by the same factor according to perceptibility constraints in the same image. As stated, we have used the values suggested in [2], and a further study of these parameters is outside the scope of this paper.
None of the attacks discussed in Section 2.3, nor the MX attack, are effective against the preprocessor. Hence, the interesting attacks for further study are the hybrid attacks, the MMX attack with nonzero threshold, and the Uniform noise attack. The Uniform attack is a special case of the hybrid attack.
5.1. The Zhao et al. parameters
In this section, following [2], we assume  users. We have used Uniform noise with scaling factor
users. We have used Uniform noise with scaling factor  , and Gaussian noise with power
, and Gaussian noise with power  . The MMX-1 attack is with
. The MMX-1 attack is with  , and MMX-2 with
, and MMX-2 with  . The hybrid attacks are with
. The hybrid attacks are with  .
.
The results, shown in Figures 12 and 13, confirm what we have seen before. There is little difference between the different decoders, and the best attacks achieve error rates  against the best decoder. It seems that the parameters of [2] suffice to ensure reasonable robustness against known nondesynchronising attacks. However, we have also confirmed that with our novel attacks, properly tuned, the preprocessing algorithm does not improve detection.
against the best decoder. It seems that the parameters of [2] suffice to ensure reasonable robustness against known nondesynchronising attacks. However, we have also confirmed that with our novel attacks, properly tuned, the preprocessing algorithm does not improve detection.

Large simulation with  users and
users and  tests. Noise attacksUniform attackMMX-1MMX-2Uniform/RandNeg hybridUniform/MX hybrid
tests. Noise attacksUniform attackMMX-1MMX-2Uniform/RandNeg hybridUniform/MX hybrid

Large simulation with  users and
users and  tests, with
tests, with  statistic decoding only. Error rateDistortion
statistic decoding only. Error rateDistortion
It is also confirmed that averaging with uniform noise is among the most efficient attacks. It is not feasible to run enough simulations to determine the optimal noise power or MMX thresholds for every number  of pirates. Thus, this simulation is insufficient to determine if one attack is strictly better under any given conditions.
of pirates. Thus, this simulation is insufficient to determine if one attack is strictly better under any given conditions.
The choice of decoding heuristic seems to matter very little, although the  statistic is consistently outperformed. No clear distinction can be made between the
statistic is consistently outperformed. No clear distinction can be made between the  and
and  statistics. In Figure 13 we show only
statistics. In Figure 13 we show only  decoding.
decoding.
5.2. List decoding
Since list decoding is more popular than maximum heuristic decoding in the fingerprinting literature, we will have a brief look at this as well, for comparison.
We have seen that the Uniform noise attack (scale  ) gives an error rate of about
) gives an error rate of about  with
with  colluders using maximum heuristic decoding (
colluders using maximum heuristic decoding ( at
at  ). The resulting
). The resulting  distortion (not normalised) is about 100–150. This is slightly less distortion than the RandNeg attack at
distortion (not normalised) is about 100–150. This is slightly less distortion than the RandNeg attack at  and slightly more at
and slightly more at  . Simulations are shown in Figure 14.
. Simulations are shown in Figure 14.

List decoding performance. The left-hand figures show the probability of at least one true positive against the false positive rate. The right-hand figures show the average number of true and false positives for different thresholds.t = 35 returned usert = 35 error eventt = 70 returned usert = 70 error event
The experiment is conducted as follows. We generate a set  of
of  "guilty" codewords and a set
"guilty" codewords and a set  of
of  "innocent" codewords. The average of the "guilty" codewords is calculated and noise added, to give the received fingerprint
"innocent" codewords. The average of the "guilty" codewords is calculated and noise added, to give the received fingerprint  . The
. The  statistic
statistic  is calculated for every user
is calculated for every user  . This experiment is repeated 2000 times, and for each iteration
. This experiment is repeated 2000 times, and for each iteration  we keep the following data:
we keep the following data:

We estimate the expected number of false positives  and true positives
and true positives  at a given threshold
at a given threshold  , as
, as

We have plotted  against
against  for varying threshold
for varying threshold  in Figure 14 (left-hand side).
in Figure 14 (left-hand side).
The probability  of at least one correct output and the probability
of at least one correct output and the probability  of at least one false negative are estimated as
of at least one false negative are estimated as

Figure 14 (right-hand side) shows  plotted against
plotted against  for varying thresholds.
for varying thresholds.
As we can see, the different attacks have similar performances. We observe that with  and
and  , we get only
, we get only  , even in the best case for the decoder. The noise attack gives
, even in the best case for the decoder. The noise attack gives  . For
. For  colluders and
colluders and  we have
we have  against the noise attack. It follows that the total error rate in the list decoding scenario is considerably worse than it is with maximum heuristic decoding.
against the noise attack. It follows that the total error rate in the list decoding scenario is considerably worse than it is with maximum heuristic decoding.
If we require  as assumed in [2], the detection rate for the noise attack at
as assumed in [2], the detection rate for the noise attack at  is little more than
is little more than  , and at
, and at  it is about
it is about  .
.
5.3. Scalability
So far we have considered very small codes, which are unlikely to be of practical use. One real application of fingerprinting is for the issue of screening copies for the academy awards ("Oscar"). (See, e.g., http://www.msnbc.msn.com/id/4037016.) In this scenario the number of users is in the order of 5000. It is hard to come up with real applications with fewer users, so we run one set of simulations for  . We assumed an averaging attack with uniform additive noise on the interval
. We assumed an averaging attack with uniform additive noise on the interval  .
.
In coding theory and communications, it is normally expected that a well-designed code can scale freely keeping the rate  constant. With
constant. With  users and the rate of the
users and the rate of the  code, we get
code, we get  . The result was an error rate of
. The result was an error rate of  , so evidently Gaussian fingerprinting does not scale well.
, so evidently Gaussian fingerprinting does not scale well.
A larger range of code parameters are shown in Table 2. Admittedly, a small sample has been used, to get results in reasonable time, but the tendency is clear and consistent. Keeping constant rate, the error rate increases dramatically when the code size increases.
 pirates, for various sequence lengths
pirates, for various sequence lengths  and numbers
and numbers  of users. Simulation based on 1000 samples.
of users. Simulation based on 1000 samples.Codebooks of  is close to the limits of what we can simulate with our current crude Matlab implementation on a 32-bit system. Codebook storage may very well be the limiting factor also for practical applications, even though somewhat larger codebooks could be made possible by a more efficient implementation. The largest codebooks that we have tried would use 400 Mb at single precision. Significantly larger codebooks would probably have to be generated on the fly by a pseudorandom number generator, so that only the seed has to be stored.
is close to the limits of what we can simulate with our current crude Matlab implementation on a 32-bit system. Codebook storage may very well be the limiting factor also for practical applications, even though somewhat larger codebooks could be made possible by a more efficient implementation. The largest codebooks that we have tried would use 400 Mb at single precision. Significantly larger codebooks would probably have to be generated on the fly by a pseudorandom number generator, so that only the seed has to be stored.
6. CONCLUSION
We have performed an extensive experimental analysis of collusive and noise attacks on Gaussian spread-spectrum fingerprinting, and introduced a couple of novel attacks. Below, we will itemise what we consider the main outcomes of our study, as well as the key questions left open.
6.1. Observations made
-
(i)
The MX attack introduced in [3] is effective against common decoders with
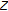 ,
,  , or
, or 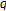 statistics. However, it is not effective against the preprocessor of Zhao et al.
statistics. However, it is not effective against the preprocessor of Zhao et al. -
(ii)
The parameters suggested by Zhao et al. appear to give a fairly robust system against known (nondesynchronising) attacks.
-
(iii)
The uniform attack, as well as hybrid attacks based thereon, break the Zhao et al. preprocessor.
-
(iv)
Averaging combined with Gaussian noise is not an effective attack compared with the other attacks studied.
-
(v)
Averaging combined with Uniform noise is very effective. It seems to outperform the other attacks considered under most, if not all, conditions.
-
(vi)
Gaussian fingerprinting does not scale well from an information theoretic perspective.
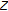 ,
,  , or
, or 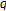 statistics. However, it is not effective against the preprocessor of Zhao et al.
statistics. However, it is not effective against the preprocessor of Zhao et al.Based on these observations, we conclude that the analysis of new fingerprinting schemes requires attention to a wider range of possible attacks than those considered in the literature. We have introduced a number of attacks worth mentioning, but we do not claim to have found them all.
6.2. Questions left open
The most interesting question left open by this study is a theoretical analysis of the attacks presented. This is expected to be slightly harder than the analysis of previous attacks [2], leading to more complicated formulae.
From an applied viewpoint, a more important question is how a complete fingerprint system can be designed. Very little research exists on watermarking robust against desynchronising attacks, and nobody has yet considered a combination of collusion attacks and desynchronisation. In a real scenario, the attackers will have such attacks at their disposal in addition to what we have studied.
In our analysis we have been assuming that the correct preprocessor mode can be easily determined, and we also supposed that it can be extended for a three-peak histogram. At present this is, at best, true using manual inspection. Further research is needed to implement automatic histogram analysis and application of the optimal preprocessor. It is also an open question if sufficient information is available from the histogram.
Another open direction in research is the application of collusion-secure codes (e.g., [4, 6, 9]) in a practical watermark/fingerprint system. Since Gaussian fingerprints do not scale well, they may have to be combined with an outer,  -ary, collusion-secure code. In this case,
-ary, collusion-secure code. In this case,  Gaussian sequences would be used to represent the
Gaussian sequences would be used to represent the  -ary symbols of the outer codewords.
-ary symbols of the outer codewords.
References
Wagner NR: Fingerprinting. Proceedings of the IEEE Symposium on Security and Privacy (SP '83), April 1983, Oakland, Calif, USA 18-22.
Zhao H, Wu M, Wang ZJ, Liu KJR: Forensic analysis of nonlinear collusion attacks for multimedia fingerprinting. IEEE Transactions on Image Processing 2005,14(5):646-661.
Schaathun HG: Attack analysis for He&Wu's joint watermarking/fingerprinting scheme. In Proceedings of the 6th International Workshop on Digital Watermarking (IWDW '07), December 2007, Guangzhou, China, Lecture Notes in Computer Science. Volume 3304. Springer; 134-145.
Boneh D, Shaw J: Collusion-secure fingerprinting for digital data. IEEE Transactions on Information Theory 1998,44(5):1897-1905. 10.1109/18.705568
He S, Wu M: Joint coding and embedding techniques for multimedia fingerprinting. IEEE Transactions on Information Forensics and Security 2006,1(2):231-247. 10.1109/TIFS.2006.873597
Schaathun HG: On error-correcting fingerprinting codes for use with watermarking. Multimedia Systems 2008,13(5-6):331-344. 10.1007/s00530-007-0096-7
Guth H-J, Pfitzmann B: Error- and collusion-secure fingerprinting for digital data. In Proceedings of the 3rd International Workshop on Information Hiding (IH '99), September-October 1999, Dresden, Germany, Lecture Notes in Computer Science. Volume 1768. Springer; 134-145.
Zhao H, Wu M, Wang ZJ, Liu KJR: Nonlinear collusion attacks on independent fingerprints for multimedia. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '03), April 2003, Hong Kong 5: 664-667.
Tardos G: Optimal probabilistic fingerprint codes. Journal of the ACM 2008,55(2, article 10):1-24.
Schaathun HG, Fernandez M: Boneh-Shaw fingerprinting and soft decision decoding. Proceedings of the IEEE Information Theory Workshop (ITW '05), August-September 2005, Rotorua, New Zealand 183-186.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Schaathun, H. Novel Attacks on Spread-Spectrum Fingerprinting. EURASIP J. on Info. Security 2008, 803217 (2008). https://doi.org/10.1155/2008/803217
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2008/803217